






If you’re preparing for system design interviews, you need to know the kinds of questions top tech companies actually ask so you can strategically prepare for them.
That’s why we’ve prepared this guide. Here you’ll find the top 5 most common system design questions with answer samples so you can see what a strong interview looks like. We’ve also gathered a comprehensive list of questions per company, insights and tips from interview experts, and a solid prep plan.
Here’s an overview of what we’ll cover:
- How to answer a system design interview question
- 5 Most common system design interview questions
- Interview performance expectations: what is expected per level
- What is the difference between high-level design (HLD) vs. low-level design (LLD)?
- More system design questions per company
- System design interview tips
- How to prepare for system design interviews
Click here to practice 1-on-1 with system design ex-interviewers
Let’s get started!
1. How to answer a system design interview question↑
1.1 What is a system design interview?
A system design interview is typically 45-60 minutes long and begins with a broad prompt, like "Design Instagram.” You’re expected to generate a high-level design, showing the different required system components. You then need to describe how they're connected, and any trade-offs in your approach.
The goal of the interview is to test how well you design scalable, maintainable systems that can function in a massive, fast-paced environment. Building a technically sound solution is key, but equally as important is your ability to consider business needs, user experience, and internal resources.
We’ll go deeper into system design interviews, including interview expectations per level and HLD vs. LLD, in later sections.
Next, let’s look at an effective answer framework you can use to structure your answer, with a sample answer outline from a system design interview coach.
1.2 FAANG-level answerframework for any system design interview question
When answering a system design interview question, you’ll want to showcase your creativity but in a structured way. To achieve this, you should practice using a repeatable framework. Below is a quick overview of our recommended 4-step approach.

Here is a more detailed walk-through of this answer structure from Ramprasad (ex-Meta engineer and interview coach), including insights and crucial information to cover for each step:
4-Step System Design Answer Framework: Walk-through
System design interview questions are meant to be vague. It appears like they're trying to ask you to boil an ocean when they ask you a question like “Design Twitter” or “Design YouTube.” It’s a whole company; how can one engineer design that?
Think of it this way: the interviewer's responsibility is to give you a question that’s very vague and complicated, while your responsibility as a candidate is to make sure that it is as simplified as possible.
Step 1: Clarifying requirements
So now, how do you simplify the problem? That is the first skill interviewers try to evaluate in a system design interview.
When an interviewer asks you to design a calendar, what do they mean by a calendar? How big of an organization? If it's for a small organization, do you need to worry about each other's calendars or about meeting rooms? It’s how you break down the problem. This is where you say you are “clarifying or simplifying the requirements.”
What does “simplifying the requirements” mean? For any software product, you need to collect information from wherever the sources are, and you need to give it back to the people who are asking for it. In more methodical terms, they call it defining your functional requirements and non-functional requirements.
Depending on your level, I would expect you to come up with these requirements intuitively. As a junior engineer, you might stop at functional requirements. As a staff-plus engineer, fun non-functional requirements are very critical. Interviewers want to know how many you can think of on your own.
So, how do you know whether you got everything right or wrong? You would never know. Because that is not the intention. System design interviews are meant to grade people on a scaling level.
Don't worry about whether you’ve completely defined your functional and non-functional requirements. Getting an agreement on it will help. List down your requirements and confirm them with your interviewers. Or, ask for a direct hint, like, “What are your most important requirements?”
Step 2: High-level design
Next is the high-level design. High-level design for 90% of the products will be the same:
- Client-side, which gives you the information
- Server-side, which is collecting the information
- Storage layer, which stores the information
Think about your write path and your read paths. Now use your non-functional requirements: at what cadence it is coming through at high frequency, and how much distribution is coming through will determine what kind of storage layer you pick.
Step 3: Drill down on your design (low-level design)
This is the point you ask your interviewer: Is there a particular area you want me to discuss further? That's where you drill down into your low-level design and let your expertise come into play.
If you are applying for a data-focused role, focus on the storage layer. For a backend-focused role, you could discuss transactions per second. For a front-end-focused role, maybe talk about client-side handling. For an ML-focused role, your ranking algorithm, how that's going to be, and how adaptable it should be.
Step 4: Bring it all together
In the last few minutes of your interview, you’ll then want to check whether you’ve met the goals of the design, i.e., the functional and non-functional requirements.
If you have time, you can go into possible bottlenecks or issues, or ways to optimize or scale the system.
Now that you’ve seen how the answer framework can help you structure your solution, let’s take a look at more example questions and answer outlines from the system design coaches on our platform.
1.3 System design interview cheat sheet
As we’ve established, your first responsibility during a system design interview is to simplify the problem by clarifying and getting confirmation on the requirements of the design challenge.
To make sure you start off on the right track, you need to know the details you need to capture. You’d also want your assumptions and estimations to be realistic enough.
To help you make sure you cover the right information in your answer, check out the system design interview cheatsheet below prepared by coach Mark (ex-Google EM).
Click here to download the system design interview cheatsheet.
2. 5 Most common system design interview questions
In this section, you’ll find some of the most common system design interview questions asked at FAANG+ companies.
For each question, we include a mock interview video and an answer outline from a system design interview coach. We recommend working on the question first, and then checking your answer against the expert’s to find out where you can still improve.
- How would you design a messaging app?
- How would you design X.com?
- How would you design Instagram?
- How would you design a file-sharing system?
- How would you design a music streaming platform?
2.1 How would you design a messaging app?
Real-time messaging apps are a common standalone product or a built-in feature of larger systems. For this question, you might be asked to design a specific app, like Messenger, WhatsApp, or Telegram.
Take a look at a sample answer outline from Mark (ex-Google engineering manager).
1. Ask clarifying questions
- Scope: Are we focusing only on one-to-one text messaging or should we also support groups, media, voice/video, etc.?
- Functional requirements: Sending, receiving, reading messages. Should we handle message delivery acknowledgements (delivered/read status)?
- Non-functional requirements:
- Scale: Expected 10B messages/day, doubling in a year.
- Latency: < a few hundred ms for 90–95% of requests.
- Availability: “Always available” (5 nines if possible).
- Consistency: Eventual consistency acceptable
- Constraints: Mobile-first application, backend focus, APIs as entry points.
2. Design high-level
- Clients: Mobile/web apps interact with system via APIs.
- APIs: Core set — SendMessage, CheckMessages, ReadMessage, MarkAsRead.
- Traffic management: Load balancer in front to distribute requests.
- Application/API servers: Horizontally scalable, stateless, ~50–100 servers initially.
- Data storage: NoSQL database (e.g., DynamoDB/Cassandra) to handle large scale and eventual consistency.
- Message distribution: Background service (message distributor) ensures undelivered messages are routed to correct recipients.
- Core entities:
- Messages (messageId, senderId, recipientId, timestamp, status, text).
- Users (userId, metadata, sent messageIds, unread messageIds).
3. Drill down on your design
- Database choice:
- SQL pros: complex queries; cons: poor scalability at petabyte scale.
- NoSQL pros: horizontal scaling, high throughput, fits simple access patterns.
- DynamoDB chosen for managed scaling + partition key/range key support.
- Sharding strategy: Consistent hashing to partition user/message space across servers (built-in for DynamoDB).
- Message distributor:
- Continuously scans undelivered messages.
- Adds message IDs to recipient’s unread list.
- Updates status → delivered.
- Needs to scale horizontally to avoid bottleneck (multiple distributors partitioned by user space).
- Performance considerations:
- ~0.5M requests/sec at peak.
- 100-byte avg message size → ~1 TB/day → ~365 TB/year → ~1 PB in ~3 years.
- Need monitoring of latency percentiles (95th/99th).
- Bottleneck handling:
- Potential overload in scanning undelivered messages.
- Solution: separate undelivered/delivered tables OR efficient DB queries with filters.
- Reliability/availability:
- Auto-scaling servers
- Replicated storage
- Monitoring system availability in terms of “number of nines”
4. Bring it all together
- Start from scope reduction: one-to-one text messages, exclude groups/media.
- Expose APIs for message operations, behind a load balancer and horizontally scalable API servers.
- Use NoSQL (DynamoDB/Cassandra) for message/user storage, leveraging partition/range keys for fast lookups.
- Introduce a message distributor service to handle delivery asynchronously with eventual consistency.
- Plan for scaling (50–100 API servers, auto-scaling DB, multi-distributor setup).
- Monitor latency, throughput, and availability as success metrics.
- Acknowledge open issues/future extensions: group messaging, multimedia, locking/contention handling.
Check out the video below to see how Mark skillfully navigates this system design question.
2.2 How would you design X.com (formerly Twitter)?
Another common system design prompt is "Design a social media app" . This prompt allows interviewers to assess your problem-solving skills and your knowledge of system design fundamentals like reliability, scalability, availability, and performance.
For this example, let’s take a look at how Ramprasad (ex-Meta engineer and interview coach) would outline his answer to the question, “Design X (formerly Twitter):
1. Ask clarifying questions
- Functional requirements
- Users need to be able to:
- Create a profile
- Follow other profiles
- Post (let’s stick to just text)
- Share and comment on posts
- See other posts in newsfeed
- Users need to be able to:
- Non-functional requirements
- Do some key estimates to work out scalability requirements:
- How many users do we need to serve - 100 million?
- How many profiles does each person follow on average - let’s say 300
- How many posts does each user create on average - let’s say 2 per day.
- Do some key estimates to work out scalability requirements:
- Work out the transactions per second - how are you going to meet this with your design? (for traditional backend SWE candidates, this will probably be your main concern)
- Consider special users: 5% of users will have a lot of followers and their posts will receive thousands of comments and millions of likes.
2. Design high-level
Most users will use the web app, so let’s design that.
We’d use a load balancer.
- Message queue:
- The content will be coming in continuously, so we’d want a queuing system to avoid missing anything
- The data will come through the message queue
- Data storage layers:
- Different data storage layers for different pieces of the information
- This data layer has to store quite a bit of user follower network, user following network, and the content
- Ranking mechanism:
- On the read path, we need a ranking mechanism to make sure that we have what content to be given to the users when they're logged.
- Ranking algorithm to work out what content a user would be most interested in.
- Algorithm takes into account newness of content, who it’s by (need to be very up-to-date, hot content)
- Include this as a black box
- If you’re an ML candidate, you’d need to go into more detail on this.
3. Drill down on your design
- Storage layer
- Include separate databases for user data, follower networks, and content
- User information and follower relationships are stored in a relational database, with sharding if needed.
- The follower network could scale to 10 billion records.
- Split content storage
- Metadata is kept in a relational database (sharded by timestamp)
- Actual media content is stored in a NoSQL key-value store
- Recent content (last week or month) is prioritized for quick access
- Ranking algorithm
- Selects the top 20 tweets for each user based on their network and trending content, caching the results for efficiency.
4. Bring it all together
- Consider: does the final design meet the functional and non-functional requirements you established at the start? Are there any bottlenecks?
2.3 How would you design Instagram?
Let’s take a look at another social media app design task, this time for Instagram by ex-Meta data engineer, Karthik.
1. Ask clarifying questions
- Functional requirements:
- Upload/download photos/videos
- Search (by title)
- Follow functionality
- News feed
- Out of scope: Likes, comments, tags, stories, messaging.
- Non-functional requirements:
- High availability
- Globally distributed user base
- News feed latency < 1 second
- High reliability, minimal tolerance for data loss
- Scale assumptions:
- 1B total users
- 250M DAUs (~25%)
- ~25K read requests/sec (mainly news feed)
- ~250 uploads/sec (10% of DAUs post daily, avg. 200 KB/photo)
- Storage: ~5 TB/day → ~100+ TB/year
2. Design high-level
- APIs (versioned, read/write split):
- Reads
- GET /download/{id} (download media)
- GET /search?q=title
- GET /feed
- Writes
- POST /upload (upload media)
- POST /follow/{id}
- Reads
- Core services/components:
- API Gateway – single entry point, handles auth, rate limiting.
- Load balancer – geo-distributed routing to nearest servers.
- Media service – handles uploads/downloads.
- Message queue & uploader – async upload pipeline.
- Object storage – photos/videos.
- Relational DB – metadata (users, photos, follows).
- NoSQL DB – news feed storage for fast retrieval.
- Feed service – generates & serves news feed (uses cache).
- Follower service – manages follow/unfollow relationships.
- Search service – metadata search (title-based).
- CDN – speeds up downloads for global users.
3. Drill down on your design
Design storage
- Object storage (photos/videos)
- Replicated for durability and reliability.
- Handles massive scale of media (billions of objects).
- Relational DB (metadata)
- Stores user info, photo metadata, follow relationships.
- Sharded by user_id for horizontal scaling.
- Replicas for high availability.
- NoSQL DB (news feed)
- Optimized for fast feed retrieval.
- Stores precomputed feed entries with low-latency lookups.
- CDN
- Serves popular photos/videos closer to end users globally.
Design upload/download
- Upload flow
- User → API Gateway → Media service → Queue → Uploader → Object storage + Metadata DB.
- Asynchronous upload pipeline prevents user from waiting.
- Unique ID generator ensures global uniqueness of media IDs.
- Download flow
- User → API Gateway → Media service → CDN (cache-first).
- Fallback: CDN → Object storage → return to user.
- Metadata lookup in relational DB ensures correct mapping of photo IDs to storage objects.
Design newsfeed
- Feed service
- Handles user requests for personalized feeds.
- First checks cache (Redis/NoSQL).
- If outdated, triggers feed generation service.
- Feed generation
- Precomputes feeds periodically (e.g., every 15 min).
- Pulls follower lists and recent posts from DBs.
- Orders posts by recency/relevance, stores in NoSQL.
- Optimizations
- Cache feeds for sub-second retrieval.
- Power-user handling: selectively precompute feeds for subsets of followers to reduce compute load.
- User activity table guides prioritization (e.g., only generate feeds for active users).
Design following
- Follower service
- APIs for follow/unfollow events.
- Writes relationships into relational DB (Follow(follower_id, followee_id)).
- Impact on feeds
- Follow events trigger feed generator updates.
- For power users, system selectively refreshes feeds of most active followers.
- Scalability
- Sharded relational DB ensures queries like “who am I following?” remain efficient.
4. Bring it all together
-
System supports billions of users with heavy reads and moderate writes.
-
Achieves sub-second feed latency using caching, precomputation, and NoSQL.
-
Ensures global availability with CDNs, replication, and geo-distributed load balancing.
-
Uploads handled asynchronously for better UX; storage split between object, relational, and NoSQL for reliability and performance.
-
Design leaves room for future optimizations: advanced feed ranking algorithms, sharding strategies, and adaptive caching for power users.
Click here to watch Karthik tackle the system design interview question in more detail.
2.4 How would you design a file-sharing system?
If you were interviewing at Google, this question would probably be presented as "Design Google Drive". Elsewhere, it might be "Design Dropbox."
You'll need to design a system that can scale to millions of users and handle petabytes of data.
Let’s take a look at an outline of ex-Shopify EM Alex’s answer to this question.
1. Ask clarifying questions
Define scope: Google Drive / Dropbox–like system.
- Functional requirements:
- Upload files
- Download files
- Sync across devices
- Notifications for updates
- Out of scope:
- File previews (thumbnails, video playback)
- Collaborative editing (Docs-style)
- File sharing with external users
- Versioning / backups
- Platforms: Desktop, mobile, and web
- Scale assumptions:
- 100M registered users, 1M daily active users (DAU)
- 1 file uploaded per user per day (~5 MB average)
- File size limit: 10 GB/file, 15 GB/account
- Estimated storage: ~1.5 PB
- QPS: ~11 average, ~20 peak
- Daily data traffic: ~5 TB
2. Design high-level
- Core components:
- Clients (desktop, mobile, web)
- Load balancer (routes requests)
- Application servers (API logic)
- Cloud storage (e.g., S3 buckets for files)
- Metadata database (e.g., MySQL via RDS)
- Notification service (Pub/Sub or SNS)
- API Endpoints:
- Upload (multi-part/resumable uploads)
- Download (pre-signed temporary URLs)
- Get file revisions (to check for latest version)
- Flow overview:
- Upload: Client → LB → API → Pre-signed URL → Upload to storage → Confirm via API → Update metadata DB → Trigger notification.
- Download: Client → API → Pre-signed URL → Retrieve file from storage.
- Notifications: API → Notification service → Clients receive update → Fetch changes.
3. Drill down on your design
- Client responsibilities: Compression, authentication, encryption (optional), direct S3 uploads/downloads.
- Database schema:
- User (id, email, password hash, last login)
- File (id, path, hash, owner_id)
- FileVersion (id, file_id, version number, timestamp)
- Device (id, user_id, device details)
- Trade-offs and rationale:
- Compression on client (saves bandwidth vs. CPU trade-off).
- MySQL over NoSQL (consistency & simplicity).
- S3 chosen for scalability, familiarity, and pre-signed URL support.
- Scalability considerations:
- Sharding in S3 folder naming to avoid hotspots.
- CDN integration for faster downloads and caching.
- Regional replication (NA, EU, Asia data centers).
- Database replicas (master-slave, read replicas).
- Conflict resolution: Duplicate file with timestamp if simultaneous updates.
- Additional features not implemented but possible:
- Backups / versioning (leveraging S3).
- Encryption (client-side to protect against breaches).
4. Bring it all together
- Recap flows: Upload → metadata DB + storage + notifications → download by other clients.
- Non-functional goals:
- Simplicity & trust (easy to use, cross-platform).
- High availability (regional redundancy).
- Performance (low latency, CDN, compression).
- Data integrity (encryption, conflict handling).
- Future improvements:
- Premium features (file versioning, backup).
- More sophisticated folder management.
- Scaling strategies (multi-region deployments, CDN, DB replicas).
Click here to watch Alex tackle this system design interview question in more detail.
2.5 How would you design a music streaming platform?
“How would you design Spotify?” is a good way to assess candidates on multiple facets of system design, including distributed systems, recommendation systems, and more.
Let’s take a look at an outline of how ex-Google EM Mark would tackle this challenge.
1. Ask clarifying questions
- Scope: What would be the constraints for today’s system design? Finding and playing music (exclude playlists, recommendations, podcasts, social features).
- Users: Assume ~1 billion users.
- Catalog size: ~100 million songs.
- Song size: Avg. ~5 MB per song.
- Storage needs: ~500 TB raw → ~1.5 PB with 3× replication.
- Metadata size: ~100 GB for songs, ~1 TB for user data.
- Non-functional requirements:
- High availability (global users).
- Scalability (handle billions of streams).
- Low latency (seamless playback).
2. Design high-level
- High-level components
- Clients: Spotify mobile and desktop apps (primary interface).
- Entry Point: Global load balancers route users to nearest data center.
- Web/Application Servers: Handle API requests (search, playback, metadata lookup).
- Audio Storage: Blob/object store for MP3 files, replicated across regions.
- Metadata Storage: Relational DB (e.g., MySQL/RDS) for songs, artists, albums, users.
- Caching Layers:
- CDN: Distributes and caches hot tracks near users.
- In-memory caches: Reduce repeated DB hits for metadata and stream tokens.
- Device cache: Offline/local caching for frequently played tracks.
3. Drill down on your design
- Database
- Audio storage: Immutable MP3 files stored in blob storage (e.g., S3) with replication.
- Metadata DB: Relational database (e.g., MySQL/RDS) for songs, artists, and user data.
- Geo-distribution: Replicate both audio and metadata across multiple regions to serve global traffic efficiently.
- Use cases
- Search:
- Queries metadata DB for songs, artists, albums.
- Returns lists of song IDs, metadata, and storage links.
- Streaming:
- Client requests a song through the app.
- Web server retrieves file from blob store (or CDN) and streams in chunks.
- Uses persistent connections (e.g., WebSockets/HTTP streaming).
- Offline listening:
- Mobile app caches recently played tracks for playback without network.
- Search:
- Bottlenecks
- Hot content spikes: Popular releases (e.g., BTS album) create massive simultaneous requests.
- Metadata DB contention: High read volume during peak search queries.
- Network throughput: Web servers can saturate network bandwidth faster than CPU.
- Cache
- Device-level: Spotify app caches recently played tracks for offline playback.
- Edge/CDN: Caches hot songs close to end users, absorbs traffic spikes.
- Web server: In-memory cache avoids repeated DB lookups for metadata and frequently requested songs.
- Load balancing
- Distributes client requests across web/application servers.
- Metrics used: not just CPU, but also network bandwidth and number of active streams.
- Elastic scaling: Spin up/down additional servers based on real-time demand.
4. Bring it all together
- System recap:
- Spotify app → load balancer → web servers.
- Metadata lookups → relational DB.
- Audio streams → blob storage + CDN + cache layers.
- Key optimizations:
- Multi-layer caching (device, web server, CDN).
- Geo-aware replication for performance.
- Smarter load balancing based on bandwidth.
- Non-functional goals met:
- Scalability → CDN + blob storage + sharding.
- Availability → 3× replication + geo-distribution.
- Low latency → caching at multiple levels
- Extensions:
- Recommendations, playlists, podcasts.
- Real-time collaborative features.
- Advanced ranking/search infrastructure.
Watch this video to see Mark tackling this system design challenge.
3. System design interview performance: what is expected at entry, mid, and senior level↑
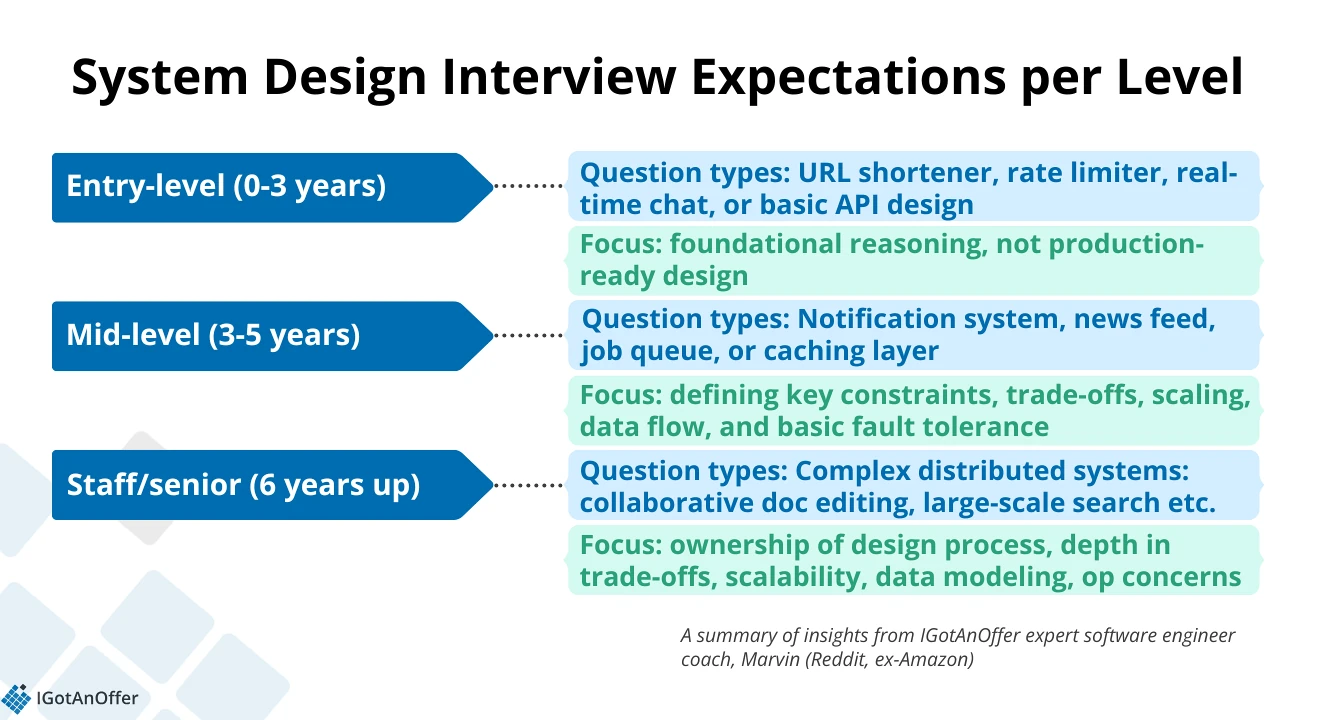
The requirements for system design interview performance vary per career level. So, to help you focus your preparation, here are the types of questions you could get and what your interviewers expect you to cover based on your level, according to our expert coach, Marvin (Reddit, ex-Amazon).
Just a quick note on our expert resource for this section: Marvin is a senior software engineer who has conducted 100+ actual and mock interviews, along with coaching sessions across all levels. He has recently gone through multiple FAANG interviews, so he’s up to date with current interview trends and expectations.
3.1 System design interviews for entry-level engineers
As a junior engineer with less than 3 years of experience, you could expect basic system design questions. The most common ones you’ll get are for a URL shortener (Design TinyURL), rate limiter, real-time chat, or any basic API design.
“At this level, interviewers typically don’t expect full architectural depth,” Marvin says. So you don’t need to provide a production-ready design. Instead, the focus will be on foundational reasoning.
You’ll need to demonstrate clarity in communication, structured thinking, and basic understanding of key components (e.g., databases, caches, queues). These matter more than getting the 'right' answer.
How to ace your system design interview as an entry-level engineer? Marvin's advice: “Asking clarifying questions and articulating trade-offs go a long way.”
3.2 System design interviews for mid-level engineers
Applying for a mid-level position requires a step up in systems thinking and component-level discussion. To assess you on these, interviewers will likely ask you to design a notification system, newsfeed, job queue, or caching layer.
During your system design interview, you should drive the conversation, define key constraints, and discuss trade-offs. Marvin says, “You’ll be expected to go deeper into scaling, data flow, and basic fault tolerance.”
Finally, according to Marvin, good signals for mid-level engineers include thoughtful simplification and an awareness of real-world constraints.
3.3 System design interviews for senior/staff engineers
The rule of thumb for SD interviews is that the more senior you are, the more system design interview sessions you’ll need to go through.
The level of complexity expected from your system design interviews also changes. At your level, you should have ownership of the entire design process, according to Marvin.
The questions you’ll get will likely be about complex distributed systems like collaborative document editing, large-scale search, or real-time analytics pipelines. Expect discussions around sharding, consistency, rate limiting, and trade-offs at scale.
“Strong candidates demonstrate depth in trade-offs, scalability, data modeling, and operational concerns,” says Marvin.
To set yourself apart from other senior candidates, you need to communicate clearly across layers and proactively identify edge cases.
If you're specifically targeting a Staff-level role, check out our Staff system design interview guide for a deeper dive into what interviewers expect at this level.
4. High-level design (HLD) vs. low-level design (LLD) ↑
High-level design and low-level design are the two main aspects of system design. In this section, you’ll learn what differentiates the two and their components, and what you’d be expected to focus on based on your career level.
4.1 High-level design or HLD
You could describe HLD as the bird’s-eye view or the big picture of an entire system architecture. With HLD, you would be expected to cover the following:
- Functional requirements: Core features (send message, post tweet, search user, etc.).
- Non-functional requirements: Scale, latency, throughput, availability, consistency.
- Traffic estimates and capacity planning: Requests/sec, storage size, growth projections.
- Architecture components:
- Load balancers
- Application/API servers
- Databases (SQL vs NoSQL, sharding, replication)
- Caches, queues, CDNs, pub/sub
- Data flows: Read path vs write path, how requests move through the system
- Trade-offs: CAP theorem, eventual vs strong consistency, cost vs scalability.
The goal of your interviewer is to assess whether you can design a reliable and scalable system that can work in real-world conditions and constraints.
4.2 Low-level design or LLD
LLD goes deeper into the details of how a system works, i.e., how the internal components are structured and work together. With LLD, you will be expected to cover:
- Object-oriented modeling: Classes, objects, interfaces, relationships
- Design patterns: Factory, Strategy, Observer, Singleton, etc.
- APIs and methods: Clear function signatures, parameters, return types
- Data models: Table schemas, indexes, relationships, how queries are optimized
- Component interactions: Sequence diagrams, how modules talk to each other
- Edge cases and validations: Error handling, retries, testing considerations
- Maintainability: Clean abstractions, modularity, extensibility
Asking you to drill down into LLD, interviewers want to see how you would translate and implement a high-level design for real-world use.
You should be able to communicate clearly and with depth, anticipate real-world constraints (and suggest ways to handle them), and reason about tradeoffs.
4.3 HLD vs. LLD - what will you cover at your level?
So, which one would you be expected to cover at your system design interview?
For freshers and entry-level engineers, a basic understanding of system design concepts is expected, but nothing too complex.
When you do look it up online, you’ll see that freshers and entry-level do get LLD questions. But these will mostly focus on testing your knowledge of Object-Oriented Programming (OOP) fundamentals, design patterns, and coding hygiene.
Typically, covering both HLD and LLD is expected in mid-level engineers. You’ll see sample answers covering both in Section 2. At this level, you’re expected to own features end-to-end, so you must be able to design APIs, schemas, AND consider scale and integration.
At a senior or staff level, you’ll mostly focus on HLD, designing systems at a scale that can serve millions of users. However, you could also be asked to drill down into LLD. You need to prove that you can bridge high-level architecture with low-level implementation.
To learn more about these two topics, we recommend reading the following deep dives:
- HLD vs LLD: The Ultimate System Design Interview Preparation Guide (by Dev.to)
- Architecture and Design 101: High-Level Design vs Low-Level Design (by Anji on Medium)
5. More system design interview questions per company↑
Here’s a comprehensive list of questions that have been asked in real tech interviews in the last few years, according to data from Glassdoor (note: we've edited to improve the phrasing of some questions).
The questions below are organized by company to help you find the most relevant ones for your interviews.
Google system design interview questions
- Design YouTube (ByteByteGo written solution)
- Design a distributed cache (written solution from Ravi Tandon)
- Design Google Maps (video solution from codeKarl)
- Design a news front page with source aggregation across newspapers
- Design Google Photos
- Design an online booking system for a restaurant
- Design an autocomplete feature with an efficient data structure
- Design a ticketing platform
- Design an elevator
- Design a Boggle solver
- How would you design a system for a robot to learn the layout of a room and traverse it?
- How would you deploy a solution for cloud computing to build in redundancy for the compute cluster?
Check out our Google system design interview guide for more questions and Google-specific insights.
Meta system design interview questions
- How would you design Instagram? (Download answer diagram)
- How would you design Twitter/X.com? (video solution)
- How would you design a chat system like WhatsApp? (ByteByteGo written solution)
- Design a live commenting system for posts
- Design Facebook status search
- How would you design an autocomplete service for a search engine?
- Design a travel booking system for Facebook users
- Design Instagram Stories
- How would you build Minesweeper?
- Design a system to prevent ads from foreign actors from interfering in domestic politics
- Design a distributed botnet
- Design a video upload and sharing app
- Design the API layer for Facebook chat
- How would you use a load balancer for memcache servers?
- How would you architect the Facebook newsfeed?
- Implement a typeahead feature
Check out our Meta system design interview questions for more questions and Meta-specific insights.
Amazon system design interview questions
- Design Snake / Chess / Tic-Tac-Toe / Poker / Boggle
- Design a parking lot
- Design a TinyURL service
- Design an API that would take and organize order events from a web store
- Design an elevator
- How would you design an electronic voting system?
- Design a deck of cards
- Design a system to optimally fill a truck
- Design a warehouse system for Amazon
- Design an online poker game
- Design a parking payment system
- Design a system to interview candidates
- Design a search engine autocomplete
- Design an airport
- Design the Prime Video home page
- Design a registration system for a restaurant
- Design a food delivery app at a global scale
- Design an inventory system
- Design a news website
- Design a shopping cart system
- Design a system to find friends on social media
- Design a Swiggy delivery system with a focus on optimizing for the shortest route
- Design a temperature identification system with geographically distributed sensors
- Design a ticketing system
- How would you design a system that reads book reviews from other sources and displays them on your online bookstore?
- Design a promotion mechanism which could give 10% cash back on a particular credit card
- How would you build software behind an Amazon pick up location with lockers?
- Design a distributed cache system (video solution)
Check out our Amazon system design interview guide for more questions and Amazon-specific insights.
OpenAI system design interview questions
- How would you build an LLM-powered enterprise search system?
- Design an in-memory database.
- Design a web hook system.
Check out our OpenAI system design interview guide for more questions and OpenAI-specific insights.
Microsoft system design interview questions
- How does buffer overflow work?
- How would you design an online portal to sell products?
- Design a new fitness wearable to measure heart rate
- Design a shopping cart
Check out our guide on Microsoft software engineer interviews for more examples.
Uber system design interview questions
- Design a heat map for Uber drivers
- Design a system to match rider and driver
- Design TripAdvisor (written answer)
- Design Google Photos (video answer front-end)
- Design YouTube feed with API
- Design a search engine (video answer)
Check out our guide to Uber engineering manager interviews for more company-specific insights and information.
Apple system design interview questions
- Design a smart elevator system that optimizes travel efficiency by grouping similar destination requests, prioritizes accessibility needs, incorporates real-time adjustments based on user input, and ensures energy-efficient operations through idle movement minimization.
- Build a blackjack gaming site
- Build Netflix (written answer)
Check out our guide to Apple engineering manager interviews for more company-specific insights and information.
NVIDIA system design interview questions
- How would you design a chatbot service that provides users with a variety of information?
- How would you perform API modeling while managing multiple servers?
- Create a memory management system that allocates fixed-size blocks, in a constrained environment with limited memory. Avoid using malloc, free, new, or delete; instead, rely on a 'memory' function for both managing memory and allocating space for clients.
- How would you design a memory allocator?
- How would you design an interface for managing and running jobs on various GPUs?
- Here is our system (description provided). How would you design it?
- How would you design a platform like Facebook or Uber?
- How would you design a proximity server?
- How would you design a shared file system that stores files in the cloud?
Check out our guide to NVIDIA software engineer interviews for more questions and NVIDIA-specific insights.
Anthropic system design interview questions
- Design the Claude chat service.
- Design a distributed search system for 1 billion documents at 1 million QPS. Cover sharding, caching, and LLM inference scaling.
- Design a batched inference system where 100 requests take the same time as 1. Use a queue to batch requests.
- Design a system that enables a large language model to handle multiple questions in a single thread.
- Design APIs for developers to access Anthropic's AI models securely and efficiently.
- Design a file-sharing / distribution system.
- Design a high-concurrency inference API / parallel processing pipeline.
Check out our guides on the most common Anthropic interview questions and Anthropic system design interviews for more company-specific information.
You can also check out the following guides for tips on role-specific system design:
- Machine learning system design interview or generative AI system design interview guides, if you're applying for an AI/ML engineering role.
- System design interview questions for product managers, if you're applying to PM-T roles
- System design interview questions for data engineers, if you're applying to data engineering roles
6. 10 System design interview tips↑
For this section, we’ve gathered tips from two of our system design interview coaches, Mark and Marvin. Collectively, they’ve conducted hundreds of interviews, both actual and mocks, at Google and Amazon. Here are their tips, based on what they’ve seen on the ground:
6.1 Communicate efficiently
45 minutes is an artificially compressed time so you need to practice communicating with the interviewer efficiently. What you don’t want is for your interviewer to wonder about what you’re working on.
“What you need to do is keep your mental model of what you’re thinking and their mental model as closely aligned as possible,” Mark says.
Your task is not to get your interviewer to agree with you on everything. Instead, you have to make sure they can follow your thought process.
This won’t come naturally, but you can get used to it with practice.
6.2 Scope the problem
In ~45mins, designing a large-scale system like Spotify is impossible. Mark’s tip is to “scope the problem to a size that you think you can complete during the interview.”
Start by clarifying the requirements with your interviewer and making clear assumptions if details are vague.
Focus on a specific, crucial part of the system, such as the backend architecture or a particular feature (e.g., if you were designing Spotify, this might be the music recommendation engine). Be ready to adjust your scope based on the interviewer's feedback.
6.3 Start drawing ~15mins in
Drawing is an important visual aid to help the interviewer understand your answer. Try to start drawing around a third of the way into the interview.
This timeframe is important to consider. Start drawing too soon and you might go down a road that doesn’t address the problem. Start too late, say 20 or 30 minutes in and you may run out of time to finish drawing.
6.4 Start with a simple design
Marvin says that candidates often make the mistake of designing for an unrealistic scale without grounding in problem constraints, and not prioritizing or evolving the design incrementally.
To avoid this, Mark’s advice is to get to a working solution first, then iterate. Don't get sidetracked and add requirements that didn't exist in the question. These will complicate your design. You can always mention something and come back to it later.
6.5 Properly understand the problem
“It’s very tempting for us engineers to hear somebody describe a problem and immediately go into solutions mode,” Mark says. This is natural, as this is what engineers have been trained to do.
However, this prevents you from truly understanding the problem and might even prevent you from catching some wrong assumptions.
So his tip is to imagine you're calling your own APIs and think about specific use cases. This will help you ensure you really understand what the problem is and what the objective is. It can help you catch assumptions you’ll likely make in your instant solution mode.
This will also help you avoid the mistake of glossing over trade-offs, failure scenarios, or state consistency, which is another common mistake Marvin has observed.
6.6 Practice, practice, practice!
There is a knowing and doing gap with system design interviews. Learning the theory and reading prep guides is great, but you need to practice out loud with friends or experts, or at least record yourself and watch yourself back.
Another benefit to practicing that Mark has observed in his clients is increased confidence and lessened stress.
If you do some mock interviews, which are hugely helpful, ideally allow time for a long feedback and conversation afterward.
6.7 Explain your thinking
Give your reasons as to why you're making each choice you do. Why did you choose one particular technology over another one?
As an interviewer himself, Mark says that he wants to understand what's behind a candidate’s thinking in order to assess their level of technical judgment.
“Not only do you understand why you're making a choice and the different aspects of different technology choices, but you're also communicating it to me in a way that I can understand.”
6.8 Get comfortable with the math
For FAANG companies, scale is important in system design interviews. That means you're going to have to do some back-of-the-envelope calculations early on in your design. Get used to calculating queries per second and the storage capacity needed.
6.9 Use the drawing tool efficiently
Your drawing is a visual aid; it doesn't need to look pretty, but you do need to be able to create boxes, shapes, and arrows quickly without having to think much about it.
Try to find out which tool the company you're interviewing with will want you to use and make sure you're comfortable using it.
6.10 Utilize a range of prep resources
There are some great resources out there, so make sure you use them, ideally both written and video content. There will be some differences of opinion as there is not one catch-all "recipe" for successful system design interviews, that's normal.
For even more tips to impress your interviewer, check out this video with Mark (ex-Google EM).
7. How to prepare for system design interviews↑
As you can see from the complex questions above, there is a lot of ground to cover when it comes to system design interview preparation. So it’s best to take a systematic approach to make the most of your practice time.
Below, you’ll find a prep plan with links to free resources.
7.1 Learn the concepts
There is a base level of knowledge required to be able to speak intelligently about system design. You don't need to know EVERYTHING about sharding, load balancing, queues, etc.
However, you will need to understand the high-level function of typical system components. You'll also want to know how these components relate to each other, and any relevant industry standards or major tradeoffs.
To help you get the foundational knowledge you need, take a look at our 9-part deep dive on system design concepts. Click on the topic to go directly to the article you need.
- Network protocols and proxies
- Databases
- Latency, throughput, and availability
- Load balancing
- Leader election algorithms
- Caching
- Sharding
- Polling, SSE, and WebSockets
- Queues and pub-sub
7.2 Learn an answer framework
As we covered in Section 1, we recommend using an answer framework to structure your answer. Learn more about our recommended framework in our guide on how to answer system design questions.
Make sure to apply this framework (or any framework that works for you) when practicing. Use it on different types of questions in a variety of subjects, so that you learn how to adapt it to different situations and respond to unpredictable questions on the fly.
7.3 Know your target company
If you already have a system design interview scheduled at a specific company, take the time to familiarize yourself with how its entire interview process works.
You also want to know if they have specific requirements for their system design interviews in particular. For example:
- Google system design interviewers prefer that candidates refrain from using specific products (e.g. certain databases, load balancers, etc.). Instead, they require candidates to build from scratch. This is to make sure they know how these components work, rather than resorting to a product that takes care of certain aspects like sharding.
- Meta, on the other hand, might give you the option to choose between a system design and product architecture/design interview. Meta system design interviews are focused on large-scale distributed systems, while product design is for user-facing products, i.e., APIs, data modeling, etc.
Also, include in your research your target company’s engineering challenges. The official company websites of most FAANG companies will typically have a dedicated engineering blog like Uber and Meta.
To get started with your research, check out our interview guides for engineering roles at some of the world’s top companies.
- Meta software engineer interview guide
- Meta embedded software engineer interview guide
- Meta engineering manager interview guide
- Meta technical program manager interview guide
- Google software engineer interview guide
- Google engineering manager interview guide
- Google technical program manager interview guide
- Google site reliability engineer interview guide
- Amazon software development engineer interview guide
- Amazon software development manager interview guide
- Amazon technical program manager interview guide
- Microsoft software engineer interview guide
- Microsoft engineering manager interview guide
- LinkedIn software engineer interview guide
- Airbnb software engineer interview guide
- Uber engineering manager interview guide
- NVIDIA software engineer interview guide
- DoorDash engineering manager interview guide
- Netflix engineering manager interview guide
- Apple engineering manager interview guide
- Apple technical program manager interview guide
- Anthropic software engineer interview guide
- Anthropic engineering manager interview guide
- Stripe engineering manager interview guide
You can also read our company and role-specific system design interview guides:
- Amazon system design interview
- Google system design interview
- Meta system design interview
- OpenAI system design interview
- Anthropic system design interview
- System design interview questions for product managers
- System design interview questions for data engineers
7.4 Practice answering questions
After learning the concepts and watching mock interview videos, it’s time to practice answering system design questions
Start with the question list in this article and the framework we’ve recommended to help you structure your answers.
To help you make sure you cover the right information in your answer, coach Mark (ex-Google EM) has kindly prepared a system design interview cheatsheet for your quick reference.
Click here to download the system design interview cheatsheet.
7.4.1 Practice by yourself
A great way to start practicing is to interview yourself out loud. This may sound strange, but it will significantly improve the way you communicate your answers during an interview.
Use a piece of paper and a pen to simulate a whiteboard session, or use a whiteboard if you have one. There are also online whiteboarding tools like Excalidraw, Visual Paradigm, or Sketchboard.me, which are particularly useful for practicing for virtual interviews.
Play the role of both the candidate and the interviewer, asking questions and answering them, just like two people would in an interview. Trust us, it works.
7.4.2 Practice with peers
Once you've done some individual practice, we strongly recommend that you practice with someone else interviewing you.
If you have friends or peers who can do mock interviews with you, that's an option worth trying. It’s free, but be warned, you may come up against the following problems:
- It’s hard to know if the feedback you get is accurate
- They’re unlikely to have insider knowledge of interviews at your target company
- On peer platforms, people often waste your time by not showing up
For those reasons, many candidates skip peer mock interviews and go straight to mock interviews with an expert.
7.5 Practice with experienced system design interviewers
In our experience, practicing real interviews with experts who can give you company-specific feedback makes a huge difference.
Find a system design interview coach so you can:
- Test yourself under real interview conditions
- Get accurate feedback from a real expert
- Build your confidence
- Get company-specific insights
- Save time by focusing your preparation
Landing a job at a big tech company often results in a $50,000 per year or more increase in total compensation. In our experience, three or four coaching sessions worth ~$500 make a significant difference in your ability to land the job. That’s an ROI of 100x








{kind=link}