No matter what role you're applying for, you can expect OpenAI interview questions to be tough. To get the job, your answers will need to be outstanding.
If that sounds daunting, don't worry, we're here to help. We've helped thousands of candidates get jobs at top tech companies, including OpenAI, and we know what sort of questions you can expect in your interview.
Below, we'll go through the most common OpenAI interview questions and show how you can best answer each one.
- OpenAI interview process
- Top 7 OpenAI interview questions and example answers
- More OpenAI interview questions (by role)
- How to prepare for an OpenAI interview
Let’s dive right in!
Click here to practice 1-on-1 with an expert interview coach.
1. OpenAI interview process↑
Before we look at the most common OpenAI interview questions, let’s first take a look at the company’s interview process.
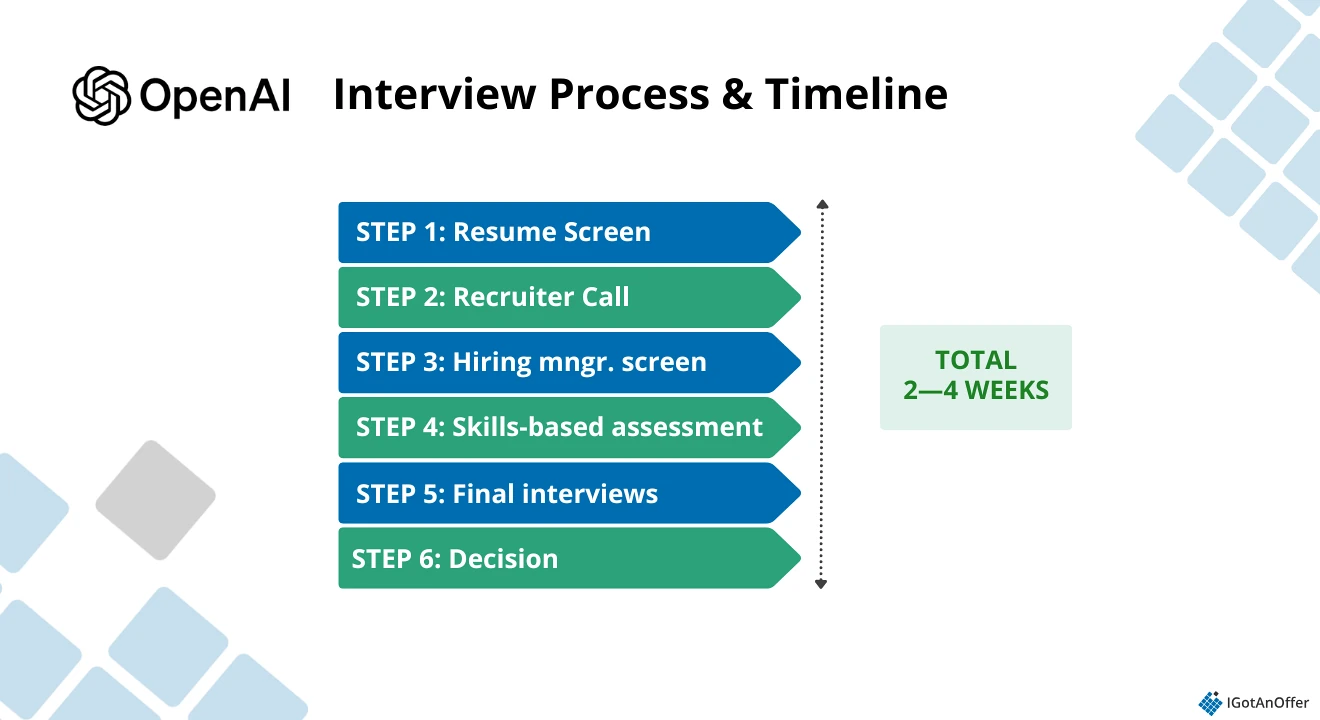
- Resume screen
- Recruiter call
- Hiring manager screen
- Skills-based assessment
- Final interviews
- Decision
1.1 Resume screen
The first step of the OpenAI interview process is the resume screen.
Here, after you’ve submitted your application through the OpenAI jobs portal or been contacted directly via email or LinkedIn, recruiters will evaluate your resume to see if your experience aligns with the open position.
This is an extremely competitive step. To help you put together a targeted resume that stands out from the crowd, check out our resume guides:
- Tech resume examples
- Software engineering resume examples
- Machine learning engineer resume examples
- Engineering manager resume examples
- Product manager resume examples
- Technical program manager resume examples
Use the guides above as a starting point for you to make a competitive resume for free.
If you’re looking for expert feedback, you can also get help on your resume from one of our tech recruiters, who will cover what achievements to focus on (or ignore), how to fine-tune your bullet points, and more.
According to OpenAI’s interview guide, this process should take about a week, but also be prepared to wait a little longer to hear back.
1.2 Recruiter call
If your resume passes through the resume screen, an OpenAI recruiter will reach out to you to schedule a call.
Usually, the recruiter call will be about the different opportunities that you might be a good fit for. During the call, expect questions like, “Tell me about yourself,” “Why OpenAI?”, and “Walk me through your resume.”
You may be asked to discuss your work and academic experience, motivations, and goals. Familiarize yourself with OpenAI's recent work, too, especially updates related to the team you're interviewing for. You can find OpenAI's latest research and product updates on their blog.
The recruiter will also discuss with you how the overall interview process will work. If you have any specific questions (e.g., timeline, location, clarification about the job description), now is the time to ask.
If all goes well, the recruiter will get back in touch with you to schedule your interview with the hiring manager.
1.3 Hiring manager screen
Depending on the role, the hiring manager screen could ask behavioral and resume questions, as well as technical questions about machine learning theory and other basic ML topics.
Be prepared to answer questions about your background (academic and/or professional) and your long-term goals.
If you’re applying for a research position, be prepared to talk about your research and any related publications.
1.4 Skills-based assessment
Depending on the role, you might get the skills-based assessment before your hiring manager screen or after.
There are different types of assessments you might encounter. According to OpenAI’s interview guide, they can come in the form of pair coding interviews, take-home projects, HackerRank tests, etc.
If you pass these assessments, you’ll then be asked to discuss or review them with a team member or hiring manager during a separate phone screen.
For engineer and other technical roles, you might get another coding phone screen once you pass the initial assessment.
1.5 Final interviews
Once you pass the assessments and initial screens, you’ll then advance to a round of final interviews.
Generally, OpenAI’s final interviews are done virtually, but you can also choose to interview onsite at their San Francisco headquarters.
Depending on the role, you can expect 4–6 hours of final interviews with 4–6 people over 1–2 days, according to their official guide.
1.6 You get an offer
OpenAI says you can expect the result one week after your final interview.
But as with most tech companies, expect to wait a little longer, and don’t hesitate to reach out to your recruiter for updates.
During this stage, your recruiter may ask for your references, so be ready with them.
An important thing to note: OpenAI doesn’t negotiate salaries with its “simple salary-plus-equity” model.
What this means is that if you get an offer, you can expect to get a flat salary of about $300,000 and a yearly grant of around $500,000 in profit participation units (PPUs), a form of equity compensation.
Check out our guide to the OpenAI interview process for more information. If you’re applying for a product manager position, we also have an OpenAI PM interview guide where you’ll find more role-related insights and tips.
2. Top 7 OpenAI interview questions and example answers↑
We researched 100 reports on Glassdoor to find the top 57 most common OpenAI interview questions.
These 7 questions are typical for OpenAI interviews, and you’ll need to be prepared for them. We’ll show you why interviewers at OpenAI ask them and how to answer them.
- Why are you interested in working at OpenAI?
- Name a project/accomplishment you're most proud of.
- Solve the LRU cache problem.
- How would you design an LLM-powered enterprise search system?
- Implement a GPU scheduling system using credits
- Design an in-memory database.
- Design Slack
2.1 Why are you interested in working at OpenAI?↑
This is often one of the first questions you’ll be asked.
Why interviewers ask this question
Interviewers ask, “Why are you interested in / why do you want to work at OpenAI?” to find out how much motivation you have to last in the company’s fast-paced environment.
At OpenAI, you’ll be working on projects that will potentially impact millions of users. You’ll need to demonstrate that you can adapt and ramp up quickly in what is essentially a new frontier that has seen massive growth in recent years.
In short, you’d need to show enough motivation to thrive at OpenAI.
Showing up on interview day with a clear list of specific reasons why you’d like to work for OpenAI is a good way to show the interviewer that you fit the profile they’re looking for.
How to answer this question
In answering this question, avoid giving answers that are unstructured, too broad, and too long. To prepare well, we recommend that you do these:
- Network: Long before your interview, connect and build rapport with current OpenAI employees. Ask them what it’s like working there, why they chose OpenAI, and what is unique about it. Their answers will give you ideas for your own answer. Also, mentioning their names during your interview shows the interviewer that you’ve put in extra effort to get to know their company better.
- Personalize: If you’ve had personal experience with OpenAI in any way, talk about it. Also talk about what you value most about OpenAI and how you resonate with its mission and values.
- Bring your unique perspective: According to OpenAI’s interview guide, they’re not credential-driven. Be prepared to talk about how your unique background will help you perform and contribute to the company’s goals.
- Make it specific: Your answer should apply only to OpenAI and not any other company. If your answer can easily be used for other companies by just swapping the company names, it’s still too broad, and you need to keep working.
- Give more than one reason: Aim for two to three concise reasons related not only to OpenAI but also to your possible position and team in the company. More than these would make your answer too long; giving only one reason is not a strong enough answer.
- Talk about your team: Some of the reasons you may want to work for OpenAI as a whole need to be specific. Talk about the team and the role that you’re applying for, and why they’re a perfect fit for you.
- Keep it sincere and balanced: While you want to show enthusiasm for working with OpenAI, give real reasons and not offer empty compliments.
Example answer to "Why are you interested in working at OpenAI?"
"I’m incredibly excited about the opportunity to work at OpenAI because of the company's groundbreaking approach to AI development and its clear commitment to ensuring the technology benefits everyone.
As a data scientist with a background in machine learning, I’ve worked extensively with GPT-3 to develop predictive models that help small businesses better understand customer behavior.
One of my favorite projects involved using GPT-3 to automate product recommendations in a personalized way that significantly increased engagement for a local e-commerce platform. Seeing the real-world impact of OpenAI’s products on businesses like this reinforced my desire to be part of a company that’s making a big difference.
Beyond the technical aspects, I’m particularly drawn to OpenAI’s work culture. I’ve talked to a few people working at OpenAI and from what I’ve heard, I really appreciate the organization’s focus on collaboration and intellectual humility. In my previous roles, I’ve thrived in environments that encourage open discussion, a diversity of perspectives, and a genuine focus on learning.
From what I’ve heard about OpenAI, it seems like the kind of place where I would be able to continuously grow, challenge myself, and contribute to a mission I believe in deeply.
I’m excited about the idea of being part of a team that is not only at the cutting edge of AI research but is also dedicated to making sure these advancements are used responsibly and for the greater good."
2.2 Name a project/accomplishment you’re most proud of.↑
This is a behavioral question you’re likely to hear at any stage in your interview process, whether you’re an experienced candidate or a more junior one.
Why interviewers ask this question
Interviewers ask this question because they’re looking for a candidate who’s keen to make an impact.
Your accomplishment doesn’t have to be big. The important thing is you’re able to demonstrate how your action made a difference or a positive impact, whether it’s at work, at school, or in any of your extracurricular activities.
Additionally, interviewers ask this question to get a sense of your values and whether they align with OpenAI’s values and operating principles.
How to answer this question
We’ve developed an answer framework for behavioral questions such as the one above. It’s the SPSIL method, which stands for Situation-Problem-Solution-Impact-Lessons.
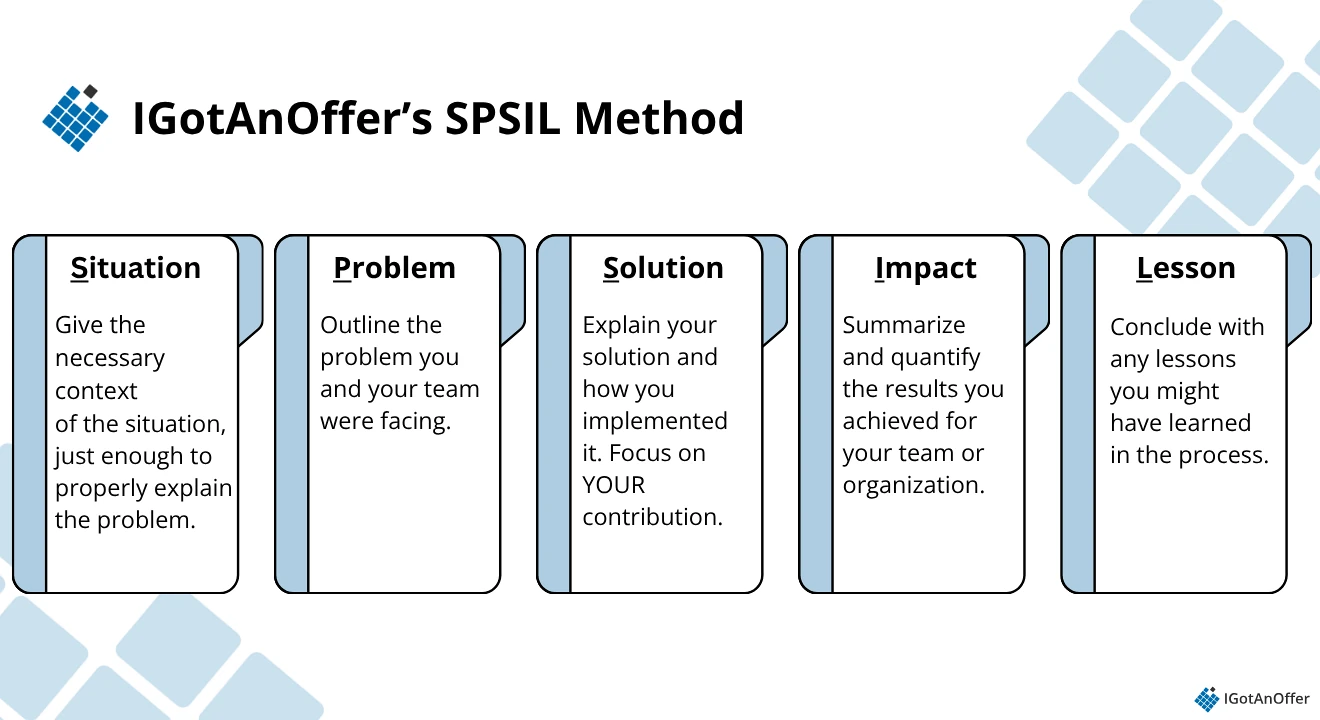
Here’s how it works:
- Situation: Start by giving the necessary context of the situation you were in. Describe your role, the team, the organization, the market, etc. You should only give the minimum context needed to understand the problem and the solution in your story. Nothing more.
- Problem: Outline the problem you and your team were facing.
- Solution: Explain the solution you came up with to solve the problem. Step through how you went about implementing your solution, and focus on your contribution over what the team / larger organization did.
- Impact: Summarize the positive results you achieved for your team, department, and organization. As much as possible, quantify the impact.
- Lessons: Conclude with any lessons you might have learned in the process.
Be sure to talk about your most recent accomplishment. If you have a few years of professional experience, don’t choose an achievement from your undergraduate years.
Let’s look at an example answer using this framework.
Example answer to "Name a project/accomplishment you’re most proud of."
#Situation
"In my previous role, I was part of a team responsible for developing a real-time data processing pipeline for a large-scale analytics platform. The platform was intended to provide insights to clients by processing massive amounts of data in real-time, such as user activity logs and sensor data. This was a critical project because it would directly affect the accuracy and speed of the insights provided to clients, which in turn impacted their business decisions.
#Problem
The existing monolithic architecture was unable to handle increasing data loads efficiently, leading to slower processing times and higher latency.
#Solution
I led the transition to a microservices-based architecture, using Kafka for real-time data streaming and integrating scalable storage solutions like AWS S3 and DynamoDB. I also introduced automated testing and CI/CD pipelines to streamline deployments.
#Impact
The new architecture reduced data processing latency by 50% and allowed the platform to handle 3x the data volume, improving overall performance and enabling faster, data-driven decision-making for clients.
#Learnings
This project deepened my understanding of scalable system design and further convinced me that building engineering solutions aligned with business goals is better if you want to achieve long-term impact."
Click here to learn more about how to answer behavioral interview questions.
2.3 Solve the LRU cache problem.↑
This is the most common coding problem OpenAI software engineer candidates get during their onsite interviews.
Why interviewers ask this question
“Solve the LRU cache problem” or “Implement an LRU cache” is a type of map interview question. Maps come up frequently in coding interviews and are fundamental to many other data structures.
How to answer this question
We've developed a coding interview framework to answer this question well. It only takes five steps:
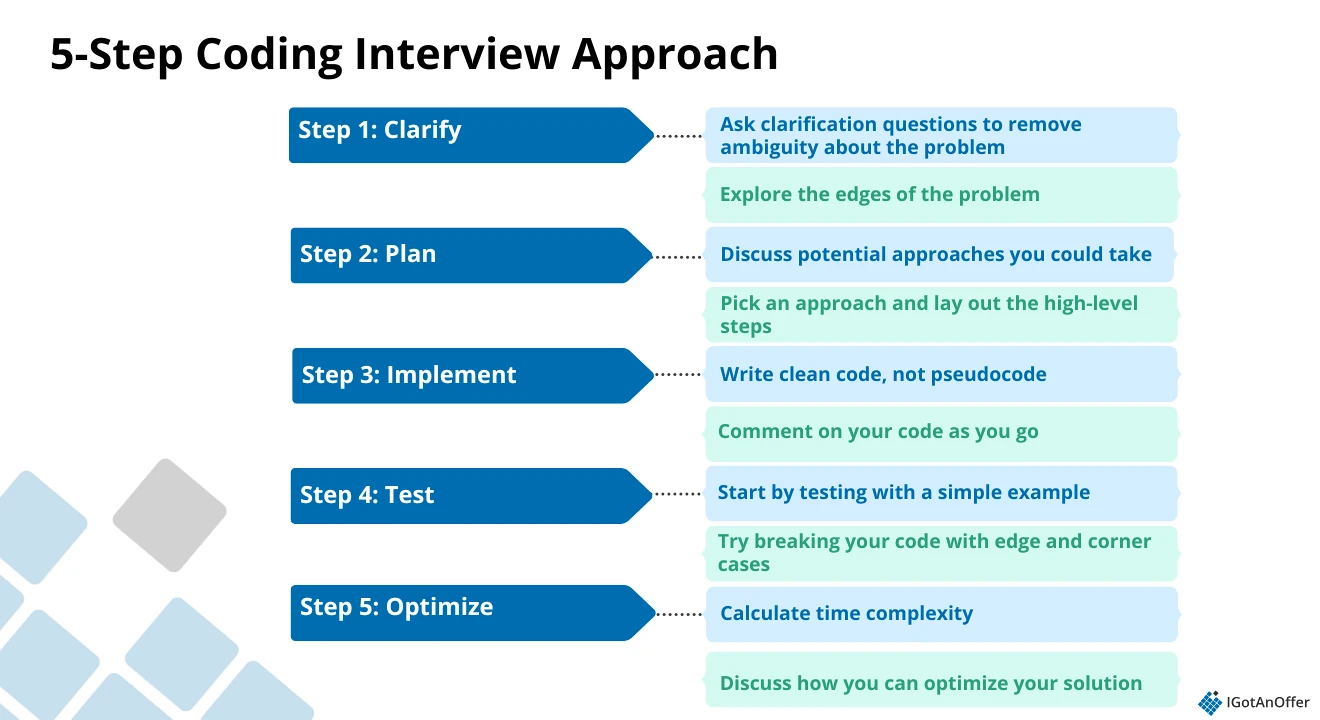
Let’s look at an example answer outline using this framework.
Example answer to "Solve the LRU cache problem."
#Clarify
Start by explaining the problem in your own words, ensuring you clarify the requirements and constraints:
- Problem: Implement an LRU (Least Recently Used) Cache, which should support two operations:
- get(key): Return the value of the key if the key exists in the cache. Otherwise, return -1.
- put(key, value): Insert the key-value pair into the cache. If the number of keys exceeds the cache’s capacity, remove the least recently used key.
- Constraints:
- Assume that both get and put operations should run in O(1) time.
- The cache has a fixed capacity.
#Plan
Before jumping into code, discuss your approach clearly:
- Data structure choice: To efficiently implement O(1) operations, we need a combination of a doubly linked list and a hashmap (dictionary in Python or a HashMap in Java).
- The hashmap stores the key-value pairs.
- The doubly linked list maintains the order of the keys, with the most recently used at the head and the least recently used at the tail.
- Operations:
- get(key): Look up the key in the hashmap. If found, move the corresponding node to the head of the list (mark it as most recently used).
- put(key, value): If the key is already in the cache, update its value and move it to the head. If the key is not in the cache, add it. If the cache exceeds its capacity, remove the node at the tail (least recently used).
#Implement
The code implements the LRU cache using Python’s OrderedDict from the collections module, which maintains the insertion order of items.
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity: int):
# Initialize an OrderedDict to store the cache and its capacity
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key: int) -> int:
# Check if the key exists in the cache
if key not in self.cache:
return -1
# Move the accessed item to the end (most recently used)
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key: int, value: int) -> None:
# If the key already exists, update its value and move it to the end (mark as most recently used)
if key in self.cache:
self.cache.move_to_end(key)
# If the cache is at capacity, remove the least recently used item
elif len(self.cache) >= self.capacity:
self.cache.popitem(last=False)
# Insert the new key-value pair
self.cache[key] = value
#Test and optimize
Test the cache by:
- Inserting and accessing keys.
- Verifying that the least recently used item is evicted when the cache reaches capacity
To optimize for time and space complexity:
Time Complexity: Both get and put operations are O(1), thanks to the efficient OrderedDict.
Space Complexity: The cache uses O(capacity) space, storing key-value pairs up to the defined capacity.
Check out our article on map interview questions where you’ll find a guide on how to solve this problem and other types of map interview questions.
To go deeper into preparing for FAANG+ coding interviews, read our coding interview prep guide.
Code refactoring
This is a notably unusual interview type and distinct from typical coding interviews. If you’re applying for a senior engineering role, you might get one of these in your technical interviews.
In a code refactoring exercise, rather than building something from scratch, you're given existing, potentially complex code and asked to improve, refactor, or optimize it. This is meant to test your ability to work with real codebases and improve existing systems.
To prepare for this challenge, you might want to have a code refactoring checklist. Below are a few helpful resources we’ve found:
2.4 How would you build an LLM-powered enterprise search system?↑
This is a system design interview question that SWE candidates are likely to encounter during the final onsite interviews.
Why interviewers ask this question
OpenAI recently said that ChatGPT's weekly users have grown to 200 million. As an SWE candidate, you’ll need to demonstrate that you’re able to design systems that are highly scalable and can keep up with the growth of OpenAI’s products.
System design interviews ask you to design distributed systems on a massive scale. Think of availability, core systems, databases, reliability, scalability, storage, partition tolerance, and related concepts.
How to answer this question
We recommend using a system design interview framework that lets you show your interviewers that you have the knowledge they need and that you can systematically break a problem down into manageable parts.
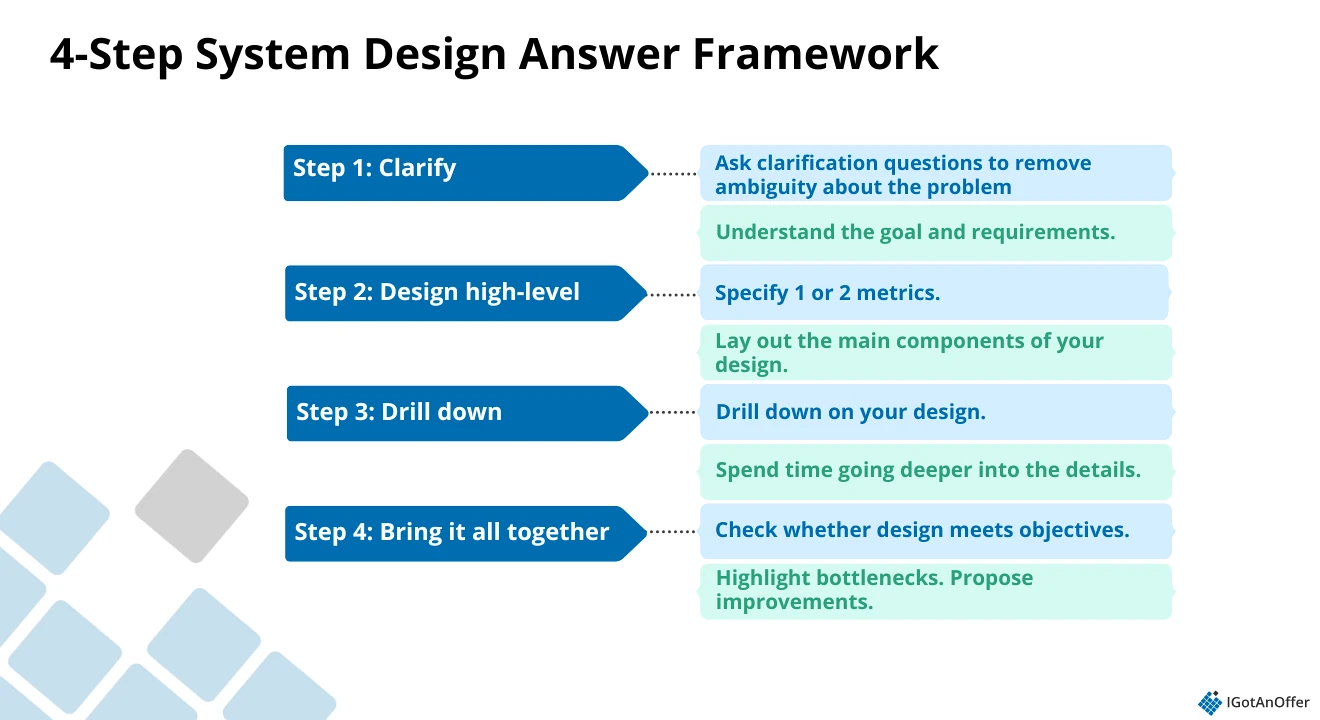
Let’s look at an example answer using this framework.
Example answer to "Build an LLM-powered enterprise search system."
#Clarify
- Functional requirements:
- Full-text search across multiple data sources (e.g., documents, emails, databases).
- Support for natural language queries (e.g., "What is the revenue for Q1 2025?").
- Advanced filtering and ranking based on context.
- Provide answers in the form of summaries or direct excerpts from the documents.
- Non-functional requirements:
- Scalability: Must handle large datasets and high query traffic.
- Real-time: Low-latency search responses.
- Security: Ensure role-based access control and data privacy.
- Accuracy: High precision in retrieving relevant documents.
#Design high-level
- LLM Integration: Use a large language model (LLM) like OpenAI's GPT, fine-tuned for the enterprise’s domain.
- Query Processing: Use the LLM to interpret natural language queries and generate relevant search results.
- Embedding Models: Use embedding models (like OpenAI embeddings or Sentence-BERT) to convert documents and queries into vector representations.
- Data storage:
- Use a search engine (e.g., Elasticsearch, Solr) for indexing and querying text data.
- Document Database: Store the actual documents (e.g., SQL or NoSQL depending on structure).
- Search pipeline:
- Data Ingestion: Collect and preprocess data (documents, emails, etc.).
- Vectorization: Use the embedding model to convert documents and queries into vectors.
- Search Engine: Perform a basic vector-based search with a ranking algorithm.
- LLM Query Handling: If needed, use the LLM to further process and refine results.
- UI/frontend: A search interface for users to input queries and receive results, providing relevant document snippets and summaries.
#Drill down on your design
Dig deeper into the components of the system.
- Data ingestion:
- Implement connectors to ingest data from multiple sources (e.g., APIs, file systems).
- Use ETL (Extract, Transform, Load) pipelines for preprocessing.
- Vectorization:
- Use embedding models to convert documents into vectors for semantic search.
- Store document vectors in a high-performance vector database (e.g., Pinecone or FAISS) for fast retrieval.
- Search engine:
- Elasticsearch or similar to handle keyword-based search.
- Combine vector search with traditional keyword search for hybrid retrieval.
- LLM query interpretation:
- Use the LLM to interpret user queries, clarify intent, and refine results (e.g., summarizing documents or re-ranking search results).
- Ranking & relevance:
- Use a combination of semantic similarity (from embeddings) and traditional keyword matching to rank documents.
- Optionally, integrate machine learning models for relevance-based ranking.
#Bring it all together by addressing potential problems and optimizations
Scalability and performance
- Horizontal Scaling: Scale the search infrastructure using load balancers and distributed systems.
- Caching: Use caching (e.g., Redis) to store frequently accessed search results and reduce latency.
- Sharding: Split document storage across multiple servers or nodes to handle large datasets.
Security
- Role-Based Access Control: Implement access control to restrict search results based on user roles.
- Data Privacy: Ensure that sensitive information is not exposed to unauthorized users.
Monitoring and logging
- Implement monitoring for query performance, error rates, and system health (e.g., using Prometheus, Grafana).
- Track and log user queries and results for continuous improvement and to train the LLM further.
Identified challenges and trade-offs
- Latency vs. Accuracy: Balancing fast query responses with the need for high-quality, accurate results.
- Data Consistency: Keeping the index and the vector database in sync with real-time data updates.
- Cost: High costs associated with using LLMs and scaling search infrastructure.
2.5 Implement a GPU scheduling system using credits↑
This is a system design interview question asked at most software engineer onsite interviews.
Many OpenAI candidates also report getting “Implement a GPU credit calculator” during the phone screen. It is simpler and does not require designing the entire scheduling system. The two are only somewhat related in that a credit calculator may be one small component of an entire GPU scheduling system.
Why interviewers ask this question
Interviewers often ask this question as this reveals whether you can handle the often ambiguous requirements and the multiple constraints of a real-world production system (i.e., non-academic). The system in the problem also reflects OpenAI’s infrastructure challenges, so it gives a good preview of the type of problem you might encounter if you do get the job.
How to answer this question
The system design interview framework we mentioned above can also be applied to this question.
Let’s take a look at how you can answer the question using the framework.
Example answer to Implement a GPU scheduling system using credits
#Clarify
Functional requirements
- Users/jobs request GPUs to run workloads.
- Each user has a credit balance that depletes while using GPUs.
- Scheduler must allocate GPUs based on credits, job priority, and availability.
- Enforce fairness: low-credit users get throttled; high-credit users proceed.
- Support job queueing, preemption, and usage reporting.
- Credits replenish periodically (e.g., daily/weekly).
Non-functional requirements
- High availability; scheduler should not be a single point of failure.
- Low latency scheduling decisions (seconds).
- Predictable fairness and isolation across tenants.
- Scalability to thousands of GPUs and many queues.
- Auditability: track how credits are consumed.
Focus on the scheduling logic, credit accounting model, and system components
#Design high-level
- API Gateway → Job submit/query, user authentication
- Scheduler Service → Core logic: placement, fairness, credit-based prioritization
- Credit Service → Maintains balances, replenishment, usage debits
- Job Queue → Pending jobs (priority queue or per-user queues)
- GPU Agent (per node) → Executes tasks, reports usage
- Monitoring/Usage Collector → Periodic GPU usage reporting to Credit Service
- Metadata Store → User credits, GPU inventory, job metadata (e.g., in PostgreSQL / Redis)
#Drill down on your design
Credit Model
- Each user has:
- Total credits
- Current balance
- Credit burn rate per GPU type (e.g., A100 > L4)
- Credits decrease proportional to:
burn_rate(gpu_type) * runtime - Replenishment via cron-like mechanism (daily/weekly replenishment windows).
Scheduling Logic
- Job arrives → check user’s credit balance.
- If insufficient credits → job queued or rejected.
- Otherwise:
- Score job based on:
- Remaining credits
- Job priority
- GPU type needed
- Fairness (e.g., weighted fair queuing / DRF)
- Score job based on:
- Place job on a GPU node with available capacity.
- Continuously monitor credit drain; if user goes negative:
- Preempt or throttle running jobs.
Job Queueing Strategy
- Multi-tenant priority queues:
- Per-user queue for fairness
- Global queue for high-priority or admin jobs
- Scheduler periodically pops from queues using a “credit-weighted fairness” algorithm.
GPU Agent
- Starts/stops jobs
- Reports:
- Utilization
- Runtime
- GPU type
- Sends heartbeat; stale nodes removed from scheduling pool.
Usage Collection + Debit Loop
- Every N seconds, collect usage → send to Credit Service
- Credit Service decrements user balances
- If negative → notify scheduler to preempt jobs on next cycle
Preemption
- Graceful drain (stop new batches) or hard kill
- Jobs can checkpoint model state periodically to avoid losing work.
#Bring it all together (problems & optimizations)
Scaling + Reliability
- Stateless scheduler behind a leader election mechanism
- Credit Service uses transactional updates to avoid double-debit
- Distributed lock or optimistic concurrency control for credit updates
- Use Redis or Cassandra for fast balance lookups
- Durable logs of usage to support audit/replay
- GPU Agents auto-recover heartbeats; nodes can join/leave cluster
Biggest Challenges & Solutions
- Credit abuse / unfairness: use audited usage logs + rate limits
- Hot users consuming everything: apply per-user caps + DRF scheduling
- Preemption cost: use time-sliced scheduling or checkpointing
- Straggler nodes: heartbeat failure → reschedule jobs automatically
- High scheduling load: shard scheduler by GPU type or region
2.6 Design an in-memory database.↑
This is another system design question that SWE candidates at OpenAI commonly get during their onsite interview.
Why interviewers ask this question
According to its interview guide, OpenAI is eager to hire experts but is also keen on candidates who may not be specialized yet but have high potential.
With this system design interview question, the interviewer is looking to probe into your knowledge of core computer concepts and how you use them to solve problems and make decisions at work. They want to know if you have the fundamental skills even if you’re not yet specialized.
How to answer this question
The system design interview framework we mentioned above can also be applied to this question.
Let’s look at an example answer outline using this framework.
Example answer to "Design an in-memory database."
#Clarify
- Functional: CRUD operations, key-value store, optional data expiry, high concurrency.
- Non-functional: Low latency, scalability, fault tolerance, memory efficiency.
#Design high-level
- In-Memory Storage: Use a hash map for fast key-value access.
- Persistence: Periodic snapshotting and/or write-ahead logs for durability.
- Concurrency: Use locks or atomic operations for concurrent access.
- Data Expiry: Implement TTL or LRU eviction for expired keys.
#Drill down on the components of your design
- In-Memory Store: Hash map or skip list for fast retrieval.
- Persistence: Periodic snapshots and logs for recovery.
- Concurrency: Read-write locks, atomic operations, or transactions for consistency.
- Eviction: TTL or LRU for automatic key expiry.
#Bring it all together by addressing potential problems and optimizations
Scalability and Performance
- Horizontal Scaling: Use sharding for large data sets, replication for availability.
- Caching: Use LRU cache for memory optimization.
- High Throughput: Ensure O(1) operation time and support batch operations.
Security
- Access Control: Role-based access control (RBAC) and encryption.
- Data Privacy: Secure data handling and access management.
Monitoring and logging
- Metrics: Monitor system health (e.g., Prometheus).
- Error Logging: Track operation failures and crashes.
- Usage Logging: Log access patterns for troubleshooting.
Identified challenges and trade-offs
- Memory Usage: Limited by RAM, mitigated with compression or overflow to disk.
- Persistence vs. Performance: Balancing durability and speed (e.g., write logs vs. snapshots).
- Concurrency: Handling concurrent writes and consistency in distributed systems.
Proposed enhancements
- Distributed Database: For horizontal scalability.
- Advanced Indexing: Secondary indexing for complex queries.
2.7 Design Slack↑
This is another common system design question OpenAI interviewers like to ask.
Why interviewers ask this question
Interviewers at OpenAI probably like to ask this question because the requirements of a modern communication app like Slack mirror the core infrastructure that OpenAI needs for LLM interactions.
How to answer this question
Again, the system design framework applies here. Let’s take a look at a sample answer using this outline.
Example answer to Design Slack
#Clarify
Functional requirements
- Real-time messaging (DMs + channels)
- Message persistence + search
- Presence indicators
- File sharing
- Notifications
- Multi-workspace + multi-device support
Non-functional requirements
- High availability
- Low latency (sub-200ms delivery)
- Horizontal scalability
- Strong consistency for message ordering within a channel
Focus: on messaging, fan-out, storage, and real-time delivery.
#Design high-level
- Clients → WebSockets for duplex communication
- API Gateway → Authentication, rate limits
- Chat Service → Handles message ingestion and fan-out
- Message Broker (Kafka/Pulsar) → Durable event log + ordered channel streams
- Channel Service → Writes messages to storage + pushes to subscribers
- Storage
- Hot path: NoSQL (Cassandra/DynamoDB) for messages
- Search: Elasticsearch/OpenSearch
- Blob store: S3/GCS for file uploads
- Presence Service (Redis + pub/sub)
- Notification Service for offline users
- CDN for file attachments
#Drill down on your design
Messaging Flow
- Client sends message over WebSocket → API → Chat Service
- Chat Service produces event to Kafka partition keyed by channel ID (guarantees order)
- Channel Service consumes events, writes to storage, and pushes to all online members via WebSocket fan-out servers
- Offline users get push notifications via Notification Service
Message Ordering
- Partition per channel = strict ordering inside channels
- No global ordering needed
Fan-Out
- “Fan-out on write”: Channel Service pushes to all active WebSocket connections
- Store user-to-server mapping in Redis for fast lookup
Presence
- WebSocket connect/disconnect triggers heartbeats
- Store active connections in Redis
- Publish updates via pub/sub → clients subscribed to presence channels
Storage
- Messages: Time-series table (partition by channel, sort by timestamp)
- Search: Write-ahead to Elasticsearch asynchronously
- Files: Upload to object storage; store only metadata in DB
Multi-Device Consistency
- Clients sync via “last read cursor” per channel
- Any missing messages pulled from storage
#Bring it all together
Scaling + Reliability
- Stateless services behind load balancers
- Kafka scaled by adding partitions (bounded by # channels)
- WebSocket fleet autoscaled
- Backpressure from Kafka if consumers lag
- Multi-AZ deployment, cross-region replication for DR
- Rate limiting & spam protection per user/workspace
Biggest Challenges & Solutions
- Hot channels: shard-based on thread or subchannel
- Exploding fan-out: batch sends, compress payloads
- Search indexing lag: async pipelines with retry queues
- Mobile offline sync: efficient delta fetch
System design interview tips
Here are more tips on how to ace your system design interview from Mark, ex-Google engineering manager.
- Communicate efficiently. 45 minutes is an artificially compressed time. You won't be used to working and talking about things at this speed and so you need to communicate with the interviewer efficiently. This takes practice. Make sure the interviewer can follow your design and your thought process.
- Scope the problem. Start by clarifying the requirements with your interviewer and making clear assumptions if details are vague. Focus on a specific, crucial part of the system, such as the backend architecture or a particular feature. Be ready to adjust your scope based on the interviewer's feedback.
- Start drawing ~15 minutes in. Try to start drawing around a third of the way into the interview. If you start drawing too soon, you probably won't yet fully understand the problem and you may go down the wrong track. If you start too late, you may run out of time to finish your design.
- Start with a simple design. Get to a working solution first, then iterate. Don't get sidetracked and add requirements that didn't exist in the question, these will complicate your design. You can always mention something and come back to it later. For example, "we'll need to use caching here but I'll come back to that later."
- Properly understand the problem. Engineers are trained to look for solutions but don't start going down this path too early. First, make sure you really understand what the problem is and what the objective is. Think about specific use cases and imagine you're calling your own APIs - this can help you catch assumptions you might have made.
- Practice, practice, practice! There is a knowing and doing gap with system design interviews. Learning the theory and reading prep guides is great but you need to practice out loud with friends or experts, or at least record yourself and watch yourself back.
- Explain your thinking. Give your reasons as to why you're making each choice you do. Why did you choose one particular technology over another one? The interviewer wants to understand what's behind your thinking in order to assess your level of technical judgment.
- Get comfortable with the math. For top tech companies like OpenAI, scale is important in system design interviews. You have to do some back-of-the-envelope calculations early on in your design. Get used to calculating queries per second and the storage capacity needed.
- Use the drawing tool efficiently. Ask your recruiter which tool you’ll be using for your interview so you can practice and get comfortable with it. Your drawing is a visual aid, it doesn't need to look pretty, but you do need to be able to create boxes, shapes, and arrows quickly without having to think much about it.
- Utilize a range of prep resources. There are some great resources out there, make sure you use them, ideally both written and video content. There will be some differences of opinion as there is not one catch-all "recipe" for successful system design interviews, that's normal.
Click here to learn more about system design interviews.
3. More OpenAI interview questions (by role)↑
We've analyzed the interview questions reported by OpenAI candidates on Glassdoor, to identify the types of questions that are most frequently asked for some of its top roles.
Below you’ll find questions reported by real candidates, plus a few more example questions that are typically asked at top tech companies. We’ve also provided links to resources you can use for your practice.
3.1 OpenAI software engineer interview questions
As an SWE candidate, you can expect a mix of coding and system design interview questions. Here are a few examples we’ve found:
OpenAI software engineer interview question examples:
Coding
- Solve the LRU cache problem/Implement LRU cache.
- Create a database ORM step by step.
- Given a simple mockup, implement that UI. Some CSS is already provided and an API to fetch the data also exists.
- Code a trivial web crawler using Go.
- Refactor a bad code.
System design
- How would you build an LLM-powered enterprise search system?
- Design an in-memory database.
- Design a web hook system.
We recommend using our prep guides on OpenAI coding interviews and OpenAI system design interviews to practice for your technical rounds.
3.2 OpenAI engineering manager interview questions
As an engineering manager candidate at OpenAI, you can expect leadership and other behavioral interview questions meant to assess your leadership experience and style.
You may also be asked some technical questions, including system design, and in some cases, coding.
Below are some of the most commonly asked engineering manager questions asked at FAANG and other top tech companies.
OpenAI engineering manager interview question examples:
- Tell me about a time you showed leadership.
- As a manager, how do you handle trade-offs?
- How do you manage your team’s career growth?
We recommend reading our guide to engineer manager interviews and our article on grokking the engineering management interview. They’re not specific to OpenAI, but reading them will be useful to get an overview of how FAANG and other top tech companies conduct interviews for this position.
We also recommend that you review the following articles on different aspects of tech leadership:
- Leadership primer for tech interviews
- People management primer for tech interviews
- Program management primer for tech interviews
3.3 OpenAI product manager interview questions
As a product manager candidate at OpenAI, you can expect standard product sense and analytics questions.
There are not a lot of interviews reported on Glassdoor for this role just yet, so below we’ve included a few of the most common PM interview questions asked at top tech companies.
OpenAI product manager interview question examples:
Product sense
- Pick your favorite app. How would you improve it? (OpenAI)
- Should Meta enter the dating / jobs market? (Meta)
- Create a social travel app with a twist. (Google)
Product analytics/metrics
- How would you measure success for OpenAI? (OpenAI)
- Facebook Events is struggling. How would you turn it around? (Meta)
- You notice a 30% change in usage of your product, what would you do? (Google)
We recommend reviewing our guide to OpenAI product manager interviews for company-specific insights. If you want to go deeper per topic, here are a few more guides with questions you can practice with:
3.4 OpenAI research scientist interview questions
For the research scientist role, you can expect a range of technical questions from coding, statistics, and ML theory. If you’ve published any research, you might also be asked questions regarding that.
OpenAI research scientist interview question examples:
- Compute KL divergence given different random variables.
- If Accuracy of Classifier is 1, what is the lower/upper bound on the loss function for a single training example?
We recommend reviewing the same references for the SWE role, and be sure to read up on OpenAI’s own research. The company’s official interview guide also recommends Deep Learning Book and Spinning Up in Deep RL.
3.5 OpenAI research engineer interview questions
For the research engineer role, you can expect questions testing your strong engineering foundations, scientific reasoning, deep ML knowledge, and end-to-end experience with research workflows.
OpenAI research engineer interview question examples:
- Do you have any experience with PyTorch?
- Describe your past research experience
- How do you handle missing data in Pandas?
3.6 OpenAI data scientist interview questions
For the data scientist role, expect questions testing your technical foundation, including your coding and data manipulation skills and statistical knowledge.
There are very few interview reports for this role. So here’s a mix of questions asked at most FAANG companies that you might also encounter at OpenAI:
OpenAI data scientist interview question examples:
We recommend reviewing our data science interview prep guide as a way to kickstart your preparation.
3.7 OpenAI solutions architect interview questions
As a solutions architect, your primary responsibility is working with enterprises and developers to ensure that the deployment of Generative AI applications is safe and effective. Given the requirements of the role, expect questions evaluating customer-facing skills, deep technical expertise, and LLM-specific reasoning.
OpenAI solutions interview question examples:
- Do you have any experience working with APIs?
- Are you used to working with C-suite executives?
- What’s the most recent challenge you’ve faced?
Be sure to familiarize yourself with OpenAI's enterprise solutions when prepping for this interview.
4. How to prepare for an OpenAI interview↑
We've coached more than 20,000 people for interviews since 2018. Based on what we’ve learned, below are the three activities you can do to prepare for interviews at top tech companies like OpenAI:
4.1 Learn by yourself
Learning by yourself is an essential first step. We recommend you make full use of the free prep resources on this blog, like the ones we’ve referenced above. Here are a few more interview guides you might find helpful during your prep:
OpenAI
- OpenAI interview process & timeline
- OpenAI system design interview
- OpenAI behavioral interview
- OpenAI coding interview
- OpenAI product manager interview
- OpenAI software engineer interview
- OpenAI data scientist interview
- How to answer "Why OpenAI?" interview and application question
Others
- Behavioral interview questions
- Coding interview prep
- Coding interview examples with answers
- System design interview questions
- ML system design interview questions
- Generative AI system design interview questions
- AI engineer interview questions
- AI product manager interview questions
If you're looking into other AI/ML-forward tech companies, we recommend reading the following company-specific guides:
Nvidia
Anthropic
- Anthropic interview process
- Anthropic culture interviews
- Anthropic system design interviews
- Anthropic product manager interviews
- Anthropic engineering manager interviews
- Anthropic software engineer interviews
- 30+ common Anthropic interview questions and how to answer them
- How to answer "Why Anthropic" interview and application question
- How to get a job at Anthropic
Once you’re in command of the subject matter, you’ll want to practice answering questions.
But by yourself, you can’t simulate thinking on your feet or the pressure of performing in front of a stranger. Plus, there are no unexpected follow-up questions and no feedback.
That’s why many candidates try to practice with friends or peers.
4.2 Practice with peers
If you have friends or peers who can do mock interviews with you, that's an option worth trying. It’s free, but be warned, you may come up against the following problems:
- It’s hard to know if the feedback you get is accurate
- They’re unlikely to have insider knowledge of interviews at your target company
- On peer platforms, people often waste your time by not showing up
For those reasons, many candidates skip peer mock interviews and go straight to mock interviews with an expert.
4.3 Practice with experienced interviewers
In our experience, practicing real interviews with experts who can give you company-specific feedback makes a huge difference.
Find an expert tech interview coach so you can:
- Test yourself under real interview conditions
- Get accurate feedback from a real expert
- Build your confidence
- Get company-specific insights
- Learn how to tell the right stories better
- Save time by focusing your preparation