Load balancing is an important concept in system design, and it’s also a common topic that comes up on system design interviews for tech roles.
Load balancing is the process of distributing tasks over a set of computing nodes to improve the performance and reliability of the system. A load balancer can be a hardware or software system, and it has implications for security, user sessions, and caching.
This is a simplified definition, so to fill in the gaps, we’ve put together the below guide that will walk you through load balancing and how you should approach the topic during a system design interview. Here’s what we’ll cover:
- Load balancing basics
- Types of load balancers
- Load balancing algorithms
- Load balancers and security
- Example load balancing questions
- System design interview preparation
Click here to practice 1-on-1 with ex-FAANG system design interviewers
1. Load balancing basics
There are two main types of Load Balancers (LB), their names referring to layers in the OSI model of network communication. L4 LBs operate at Layer 4, the transport layer, and L7 LBs operate at Layer 7, the application layer. We’ll discuss the tradeoffs between which layer an LB operates at more in Section 2.2.
There are many algorithms for deciding exactly how to distribute tasks. The most commonly used classes of algorithms are Round Robin, Least Load, and User and Resource Hashing. Some of these methods are only available on L7 LBs.
1.1 Advantages of load balancing
- Enable horizontal scaling: spinning up multiple instances of a service is not possible without a load balancer directing traffic efficiently to the cluster.
- Dynamic scaling: it's possible to seamlessly add and remove servers to respond to load.
- Abstraction: the end user only needs to know the address of the load balancer, not the address of every server in the cluster.
- Throughput: service availability and response time are unaffected by overall traffic.
- Redundancy: distributing load over a cluster means no one server is a single point of failure. Note that the load balancer itself must also not become a single point of failure.
- Continuous deployment: it's possible to roll out software updates without taking the whole service down, by using the load balancer to take out one machine at a time.
2. Types of load balancers
2.1 Hardware vs software load balancers
Hardware load balancers are specialized appliances with circuitry designed to perform load balancing tasks. They are generally very performant and very expensive. Hardware LBs are generally L4 LBs, because L7 decisions are more complex and need to be updated more often.
The most well-known and respected software load balancers are HAProxy and nginx. Software load balancers like these run on standard servers and are less hardware optimized, but cheaper to set up and run. With a software load balancer, requests are simply routed to the load balancer server instead of an application server.
2.2 DNS vs L4 vs L7 load balancers
DNS load-balancers integrate with the Domain Name Services (DNS) infrastructure to cause a client’s name lookup for a service (e.g., for “www.google.com”) to return a different IP address to each requester corresponding to one of a pool of back-end servers in their geographic location.
An L4 load balancer acts on information found in the network and transport layers of the request. This includes the protocol (TCP, UDP, etc.), source and destination IP addresses, and source and destination port numbers. The L4 LB doesn't have access to the contents of the request like application-level headers or the requested URL As a result, the routing decisions are based entirely on request headers at L4 and below. For example, an L4 LB can route requests from the same IP address to the same server every time.
L7 LBs on the other hand have access to the full information carried by the request at the application layer, and as a result they can make more sophisticated routing decisions. For example, they can route requests for video content to a pool of servers optimized for video, requests for static content to a different set of servers, etc. They can also route requests based on the user, so that the same user always lands on the same server (for session stickiness) or the same pool of servers (for performance reasons).
In order to look inside the request an L7 LB needs to handle decryption. This means the LB does TLS termination so the TCP connection ends at the load balancer. The benefit of this is it frees backend servers from having to perform decryption (a performance-intensive task) and from managing certificates. On the flipside, the load balancing layer becomes a more concentrated attack surface.
|
What |
L4 |
L7 |
DNS |
|
Data requirements |
Request packet header |
Contents of the request |
DNS lookup before request |
|
Session security |
SSL passthrough |
TLS termination |
Not impacted |
|
Implementation location |
Hardware or software |
Usually software only |
Integrated with DNS server |
|
Speed |
Fast |
Less fast but modern hardware can take it |
Fast |
|
Access to content |
Content agnostic |
Inspects and manipulates content (cookies, session management, different protocols or request types to different servers) |
Content agnostic |
3. Load balancing algorithms
Load balancing algorithms are generally divided into two groups: static and dynamic. Static algorithms function the same regardless of the state of the back end serving the requests, whereas dynamic algorithms take into account the state of the backend and consider system load when routing requests.
Static algorithms are generally simpler and more efficient to implement but can lead to uneven distribution of requests. Dynamic algorithms are more complex and entail more overhead, as they require communication between the LB and the back-end servers, but can more efficiently distribute requests.
3.1 Static
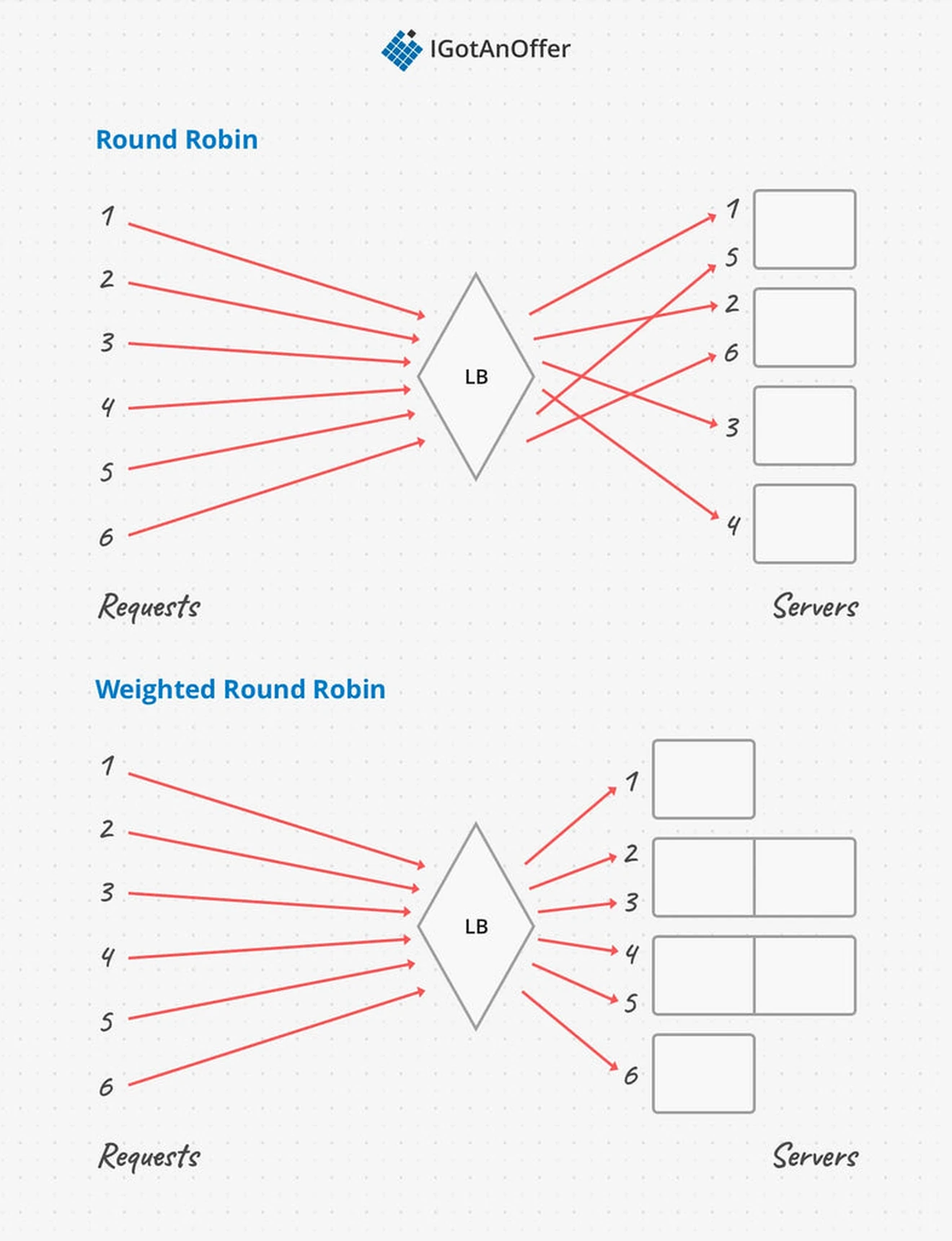
Round robin is the simplest and one of the most used algorithms. The load balancer maintains a list of available servers, and routes the first request to the first server, the second request to the second server, and so on. This works well if every server in the pool has roughly the same performance characteristics.
A “weighted” round robin takes server characteristics into account, so that servers with more resources get proportionally more of the requests. The advantages of this algorithm are that it is simple, very fast, and easy to understand. The disadvantages are that the current load of each server is not taken into account, and that the relative computation cost of each request is also not taken into account.
A Random algorithm is another simple and popular approach. Requests are sent to random servers, which can be weighted by server capacity. Random works well for systems with a large number of requests because the law of large numbers means randomization will tend towards a uniform distribution. It also works well with running several LBs at the same time, because they don’t need to coordinate.
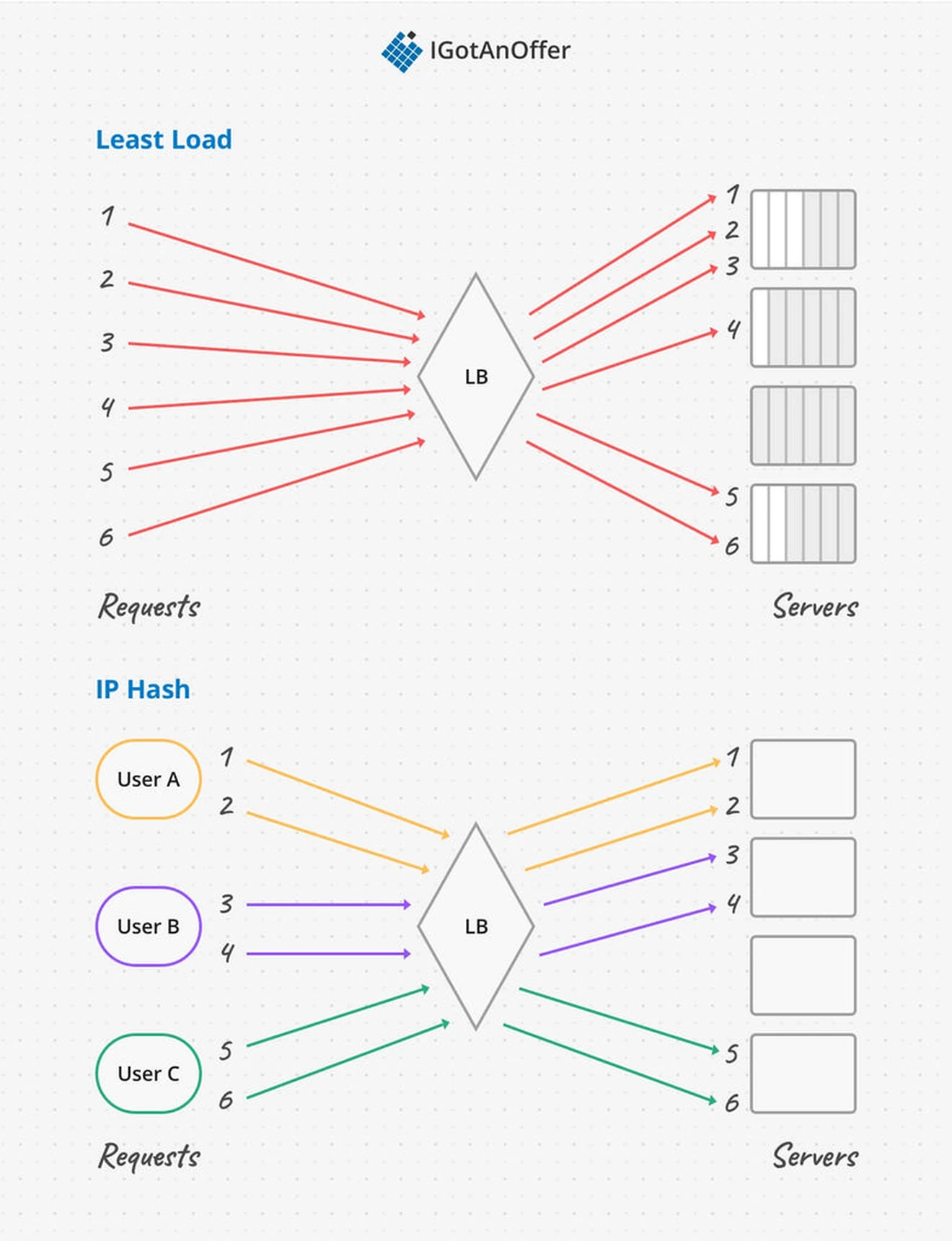
With a User IP Hashing algorithm, the same user always goes to the same server. If the assigned server ever goes down the distribution is rebalanced. In this way we get session stickiness for free, and some caching wins.
In a similar scheme, URL Hashing algorithms map requests for the same content to the same server, which helps with server specialization and caching. Since URL hashing relies on the content of requests to make load balancing decisions, it can only be implemented in L7.
3.2 Dynamic
In a Least Load algorithm, requests are sent to the server with the lowest load at the time of request. Load can be measured with a variety of metrics, including number of connections, amount of traffic, and request latency.
The “power-of-d-choices” algorithm is popular for large distributed clusters because it effectively addresses a problem that arises when we have a pool of independent load balancers instead of a single load balancer. If every LB in the pool sends a request to the least busy server, then that server will be hit with requests from all LBs and quickly become overloaded.
If every LB instead chooses a server randomly, this problem will be alleviated, but then the current server load won't be taken into account. The power-of-d-choices solution is to choose a subset of d servers at random (nginx uses d=2) and pick the best (least busy) server between them. Choosing the size of d correctly impacts the overall effectiveness of this load balancing approach.
|
Algorithm |
Kind |
Pros |
Cons |
|
(Weighted) Round robin |
Static |
Simple |
Doesn't take load into account |
|
Randomized |
Static |
Siimple, stateless |
Doesn't take load into account, requires large number of requests |
|
Hashing |
Static |
Caching, stickiness |
Requires inspecting the request |
|
Least load |
Dynamic |
Optimal use of resources |
Complex, high overhead |
|
Power-of-d-choices |
Dynamic |
Efficient when “d” is low, works with multiple LBs |
Allocation is only as optimal as Least Load when “d” approaches the total number of servers. |
3.3 Choosing an algorithm
The best load balancing algorithm depends on the needs of the system. If the server pool and the requests are both homogeneous, and there is only one balancer, then Round Robin will work well and is the default in many load balancer applications.
If the server pool is heterogeneous in computing power, then it’s useful to use Round Robin weighted by server capacity. On the other hand if the requests are heterogenous, Least Load is helpful to prevent servers from being intermittently overloaded.
When the system has a pool of load balancers, then the load balancing algorithm needs either randomness or a power of d choice algorithms to avoid all the balancers sending traffic to the currently least loaded server.
At this point you might be wondering, if there’s a pool of load balancers, who balances the balancers? One approach is to have an L4 LB in front of L7 LBs, for example putting a Round Robin balancer to a pool of Power-of-d-choices balancers.
|
Request size |
Server size |
Request volume |
Choice |
|
Uniform |
Uniform |
Low |
Round robin |
|
Uniform |
Uniform |
High |
Random |
|
Uniform |
Mixed |
Low |
Weighted round robin |
|
Uniform |
Mixed |
High |
Weighted random |
|
Mixed |
Low |
Least load |
|
|
Mixed |
High |
Power-of-d-choices |
4. Load balancers and security
Since L7 LBs need to examine the request to make routing decisions, any encrypted requests (HTTPS) need to be decrypted. That means an L7 LB will terminate the TCP connection with the request source and start a new connection to pass the request to the backend servers. This new request can be encrypted or not, depending how much you trust your backend server network.
Load Balancers are also a natural point of protection against DDOS attacks. Since they generally prevent server overload by distributing requests well, in the case of a DDOS attack the LB makes it harder to overload the whole system. They also remove a single point of failure, and therefore make the system harder to attack.
5. Example load balancing questions
The questions asked in system design interviews tend to begin with a broad problem or goal, so it’s unlikely that you’ll get an interview question entirely about load balancing.
However, you may be asked to solve a problem where it’s an important part of the solution. As a result, what you really need to know is WHEN you should bring it up and how you should approach it.
To help you with this, we’ve compiled the below list of sample system design questions, where load balancing is an important consideration.
- Design a scalable AWS system (Read the answer)
- Design Instagram (Read the answer)
- Design Pinterest (Read about how Pinterest scaled)
- Design BookMyShow (Read the answer)
- Design a Cloud Gateway for Netflix (Read the answer)
6. System design interview preparation
Load balancing is just one piece of system design. And to succeed on system design interviews, you’ll need to familiarize yourself with a few other concepts and practice how you communicate your answers.
It’s best to take a systematic approach to make the most of your practice time, and we recommend the steps below. For extra tips, take a look at our article: 19 system design interview tips from FAANG ex-interviewers.
Otherwise, you can prepare by following the steps below.
6.1 Learn the concepts
There is a base level of knowledge required to be able to speak intelligently about system design. To help you get this foundational knowledge (or to refresh your memory), we’ve published a full series of articles like this one, which cover the primary concepts that you’ll need to know:
- Network protocols and proxies
- Databases
- Latency, throughput, and availability
- Load balancing
- Leader election
- Caching
- Sharding
- Polling, SSE, and WebSockets
- Queues and pub-sub
We’d encourage you to begin your preparation by reviewing the above concepts and by studying our guide on how to answer system design interview questions, which covers a step-by-step method for answering system design questions. Once you're familiar with the basics, you should begin practicing with example questions.
6.2 Practice by yourself or with peers
Next, you’ll want to get some practice with system design questions. You can start with the examples listed above, or read our guide to system design interview questions (with sample answer outlines).
We’d recommend that you start by interviewing yourself out loud. You should play both the role of the interviewer and the candidate, asking and answering questions. This will help you develop your communication skills and your process for breaking down questions.
We would also strongly recommend that you practice solving system design questions with a peer interviewing you. A great place to start is to practice with friends or family if you can.
6.3 Practice with ex-interviewers
Finally, you should also try to practice system design mock interviews with expert ex-interviewers, as they’ll be able to give you much more accurate feedback than friends and peers.
If you know someone who has experience running interviews at Facebook, Google, or another big tech company, then that's fantastic. But for most of us, it's tough to find the right connections to make this happen. And it might also be difficult to practice multiple hours with that person unless you know them really well.
Here's the good news. We've already made the connections for you. We’ve created a coaching service where you can practice system design interviews 1-on-1 with ex-interviewers from leading tech companies. Learn more and start scheduling sessions today.