This article was written in collaboration with interview coach Suman Bukka. A former software development manager with Amazon, Suman has interviewed 500+ engineers over the course of his career. He now works as a senior engineering manager in the connected car space.
System design interview questions are intentionally ambiguous and extremely complex. Interviewers at companies like Amazon, Facebook, and Google use them to assess your technical and communication skills for top tech roles.
To help you perform at your best, we’ve put together a minute-by-minute breakdown of how to answer one of these questions, from start to finish.
Consider this your complete guide on answering system design interview questions. Here you’ll find an answer framework, the timed breakdown of a 60-minute round, as well as an example answer and an interview preparation plan.
Here’s an overview of what we’ll cover:
- System design interview framework
- Example system design interview answer
- Good vs. great system design candidates
- System design interview preparation
Click here to practice system design interviews with ex-FAANG interviewers
1. System design interview framework
To learn how to answer system design interview questions, you must first be able to approach them systematically. There are a variety of ways to solve system design questions, but at the end of the day, you need a method that will consistently:
- Show your interviewer that you have the knowledge they need
- Break the problem down into manageable steps
With that in mind, one of our favorite approaches is summarized in the following video from Amazon:
The approach shown in the video above can be boiled down into 4 main steps:
- Ask clarifying questions
- Design high-level
- Drill down on your design
- Bring it all together
Keep in mind that interviewers generally want to see your high-level design within the first 20 minutes of the round. Most system design interviews last for 45-60 minutes, which means that you’ve got to figure out how to allocate your time wisely.
So let’s jump into a minute-by-minute breakdown of the round, provided to us by one of our coaches, Suman Bukka. If you'd like to see an example of each section, click on the titles to jump to the corresponding section of our sample system design interview answer.
1.1 Ask clarifying questions (minutes 0-8)
Don’t jump straight into the system design question without consulting your interviewer. Instead, start by clarifying the goals and requirements of the system.
This will have a huge impact on the quality of your design, because the value of a system is deeply connected to how well it meets the intended objectives. Make sure that you understand these objectives, as well as the scale of the system, and which aspect of the system you should focus on.
Let’s break down how this would play out in an interview setting.
Minutes 0-5: Clarify the scope of the question
First, spend about five minutes checking in with your interviewer about the functional and non-functional requirements of what you’re going to design. Ask about the system’s goals and how they will be measured. Be sure that you fully understand the question before moving forward.
Minutes 5-8: Specify your assumptions
Next, take a couple of minutes to call out any assumptions you’re making that will influence your design approach. Speaking your thoughts out loud will let your interviewer follow your logic and steer you in the direction they most want to go. If applicable, ask about non-functional requirements such as availability, consistency, scalability, etc.
1.2 Design high-level (minutes 8-20)
Once you've clarified the requirements of the system, it's time to start designing.
In order to complete a high-level design for the system within the first 20 minutes, you’ll have to quickly clarify the requirements and include only the most foundational components (e.g. web servers, database, the front end). After that, you’ll drill down into more detailed aspects of the system.
Here’s how much time you should spend on each of these steps:
Minutes 8-11: Calculate metrics
We suggest that you start the high-level design by specifying one to two metrics (e.g. number of users added, products sold before vs after a feature launch, etc.) Then use these metrics to do some simple calculations in order to find the optimal usage pool of the system. This would include CPU, memory, IO transfer, etc. You may also want to consider connection pools or cache hit ratios.
Alternatively, you could calculate the TPS (transactions per second) for the entry point of the system and estimate TPS growth over time. This shows you can think and make decisions for a future-ready system.
Minutes 11-15: Identify high-level components or services
Once you’ve defined your metrics, map out only the most functional components of the system (e.g. front end, web server, database, etc.). Show your expertise in defining APIs by specifying REST APIs or other suitable interaction methods for the system. This would be another good time to check in with your interviewer about the level of detail with which they’d like you to explore each component.
Minutes 15-20: Design the database
Finally, before getting into the more detailed aspects of your system, make some decisions on how you will design its database. Choose whether it will be a relational or a no-SQL database, as well as its metadata and table structure. If you are proficient in NoSQL and choose NoSQL, explain which technologies would be helpful (MongoDB vs Cassandra) and compare them against the CAP theorem. Explain your reasoning for each of these decisions to your interviewer.
1.3 Drill down on your design (minutes 20-45)
Once you’ve outlined your high-level design, you should drill down into more details, starting with the component that you are most familiar with. For example, if your background is in front-end development, then you could start with the front-end, then work your way backwards through the system.
This will help ensure that you have time to go in-depth where you have the most knowledge. Similarly, it may allow you to give more general designs for areas where you're weaker, due to the time limitations of the interview.
Here’s how to divide up your time:
Minutes 20-30: Draw an architecture diagram
If you haven’t already, start mapping out the system on your whiteboard. Speak through your diagram so that your interviewer is able to follow along and ask questions when necessary. When drawing the diagram, be sure that you display only the relevant components and how they interact with each other, without clutter.
Minutes 30-35: Identify bottlenecks
Once you’ve got your architecture diagram, consider any bottlenecks that may arise when it comes to the system’s scalability, performance, or flexibility. Will it need a load balancer to handle extra user requests, or would a different API perform better with higher traffic? Mention these to your interviewer, as well as the trade-offs of your methods of addressing them.
Minutes 35-45: Dive into a specific component
To finalize your design, play to your strengths by choosing a component you’re more familiar with and drilling down on it. If you’re not sure which component would be best to explore, ask your interviewer. This is a good time to showcase your knowledge on technical aspects like specific technologies or algorithms (e.g. load balancers, API gateways, etc).
1.4 Bring it all together (minutes 45-60)
Finally, before the end of your interview, you should take a few minutes to refine your solution and highlight important improvement opportunities.
You should recap the goals and requirements you captured at the beginning of the interview, and then highlight how your solution meets those objectives. Finally, don’t forget to leave some time for the interviewer to ask you final questions, or vice versa.
Minutes 45-55: Refine the architecture
Before wrapping up the round, take about five minutes to re-examine what you’ve designed. Does it meet the objectives you laid out with the interviewer at the beginning of the session? It is okay to change some components at this stage if you think it will improve the system, but you must explain to the interviewer what you are doing and why.
Minutes 55-60: Questions for the interviewer
Congratulations! You’ve worked with your interviewer to design a scalable system. These last few minutes are for you and your interviewer to wrap up the round and ask each other any lingering questions about what you have designed, or about the job that you are interviewing for.
Now that you’ve seen a breakdown of a system design interview flow, let’s take a look at a full example answer.
2. Example system design interview answer
To illustrate the framework discussed above, we’ve laid out an example answer to a real system design question that was asked in an Amazon TPM interview, according to data from Glassdoor.
Try this question:
"Design a database for a tiny URL implementation."
System design sample answer:
Step 1: Ask clarifying questions
Clarify the scope of the question ↑
Candidate: “Okay, I’m going to restate the question first, to make sure that I understand what you’re asking me. As I understand a tiny URL system, a user will input a URL and the system will return a short ‘pointer’ URL to the full URL. It would be something like ‘https:/ /tiny. url/shortCode’. When someone visits the short URL, they will be redirected to the full URL. The service would generate ‘shortCode’ as a unique reference to the URL. Am I correct that I need to design the persistent storage component of a tiny URL system?”
Interviewer: “Yes, that’s correct.”
Candidate: “Great. To clarify, we'll need to design the data schema, database architecture, and choose a database technology to use.”
Interviewer: “Yes, that’s correct.”
Candidate: “Do we need to specify a particular brand or instance of database engine, or can we specify the technology type, e.g. relational, key-value, document, etc?”
Interviewer: “Let's keep it at the level of technology type, we don't need to specify the vendor or engine.”
Specify your assumptions ↑
Candidate: “Great, thank you. I'm assuming this system would be for a large number of users, and the links would need to be available for an extended period of time, or perhaps indefinitely? In other words, a simple in memory or local file store would not be suitable for this system.”
Interviewer: “Yes, definitely.”
Step 2: Design high-level
Calculate metrics ↑
Candidate: “Great. How many users are we catering for? Or in other words, how many URLs would we be generating each second, and how many URLs would we be serving each second? I'm assuming that it would be highly asymmetric, in that there would be many more URLs served each second than URLs generated?”
Interviewer: “Yes, it would be asymmetric. We would need to cater for a high volume of traffic, as it would be used as the default URL shortener for a popular social network, which has about 300 million daily active users.”
Candidate: “I see. Okay, let me try some rough calculations. Let's say 20%, or 60 million, users are frequent original posters (assuming that most social users consume or share existing posts). If they post something with a URL, say, once per day, then we would need to create 60 million URLs per day. 60 million / (24 hours * 3600 seconds in an hour) = 695 URLs created each second, if equally spaced across the day.”
Interview: “That's probably high for current users and usage, as not everything posted is a link, but the user base is growing, so it will be a good estimate for the next few years.”
Candidate: “Cool, we'll go with those numbers then. For URLs served, I'm assuming there would be a spread of popularity. Some shortened URLs could have zero clicks, while a few may go viral and get tens or hundreds of thousands, or even millions of clicks.”
Interviewer: “Sounds like a reasonable assumption.”
Candidate: “All right, let's assume that on average a URL would be read maybe 100 times, heavily weighted to the most popular URL. So we can say there are roughly 100 times more reads per second than writes.”
Interviewer: “Reads are definitely higher than writes, but that sounds a bit low as the ratio.”
Candidate: “Let's increase it by an order of magnitude, say, 1000 times?”
Interviewer: “Okay, sounds good.”
Candidate: “We will be generating a lot of URLs! Would we need to keep them forever, or should they expire after some time?”
Interviewer: “Hmm, I think we can expire them after some time.”
Candidate: “Okay, we'll keep track of when a URL is created, so we can remove it.”
Interviewer: “Right, ok.”
Identify high-level components or services ↑
Candidate: “Now that we know the scale that we are designing for, a single server clearly will not meet the load or availability requirements.”
Interviewer: “That’s true.”
Candidate: “Okay, so I’m thinking we’ll need multiple API or web servers, and we’ll also need multiple database servers, to create a distributed system. This way we’ll be able to meet the high demand and availability requirements.”
Interviewer: “Yes, a distributed system sounds like the way to go here.”
Candidate: “We’ve established that a few of the links will get the most traffic. This seems like a good candidate for a caching layer, so we can reduce the load on our databases and make the most-used links quicker to access.”
Interviewer: “That's a good idea.”
Design the database ↑
Candidate: “Okay, so now I’d like to determine what the data schema should look like.”
Interviewer: “Go ahead.”
Candidate: “At the minimum, we’ll be storing the full URL, so we can redirect to it, and the short code, which must be unique per URL. Since we also look up links by the short code, it could also be the primary key or identifier for the record.”
Interviewer: “Yes, the short code would be unique. Is that the only data to store?”
Candidate: “Earlier we also mentioned that links should expire, so we’d need to store a timestamp. Perhaps either the date the link should expire, or the date it was created.”
Interviewer: “Is there a difference there?”
Candidate: “If we store the date created, we’ll be able to change expiry policy parameters more easily, and enable more flexibility there. It would also be simple to report on tiny URLs created per time frame, without back calculating. If we store the expiry date though, it means we won’t need to calculate it from the created date, and that could speed up purging old records. We could store both as well.”
Interviewer: “Okay, sounds good to store both, enabling a bit of flexibility.”
Candidate: “We could also store the user that created the link, if the service records that. Do we have a user ID to store, or would it be anonymous?”
Interview: “It would be users of the social network, so they would have a user ID.”
Candidate: “Okay great. As far as I see it, we only really have one table or document, or value object to store. It would look a bit like this:”

Candidate: “We could have a bit of a problem with introducing a distributed system now, though.”
Interviewer: “What's that?”
Candidate: “Well, we need to generate a unique ‘shortCode’ for each of the URLs, right?”
Interviewer: “That's right.”
Candidate: “On a single database server architecture, that’s simple – we'd just let the database generate an ID for us. But we will be running multiple servers, or partitions, and if each server is creating an ID, we will be bound to get collisions.”
Interviewer: “That's true.”
Candidate: “So, we'll need some other scheme to come up with an ID for the ‘shortCode’. We could make a central, shared ID generator that each server can call when creating a new short code. That way we can guarantee that the generated short code will be unique.”
Interviewer: “I guess that would solve the collision problem.”
Step 3: Drill-down on your design
Draw an architecture diagram ↑
Candidate: “Okay, so I think this is the basics of what the system would look like with the major components:”
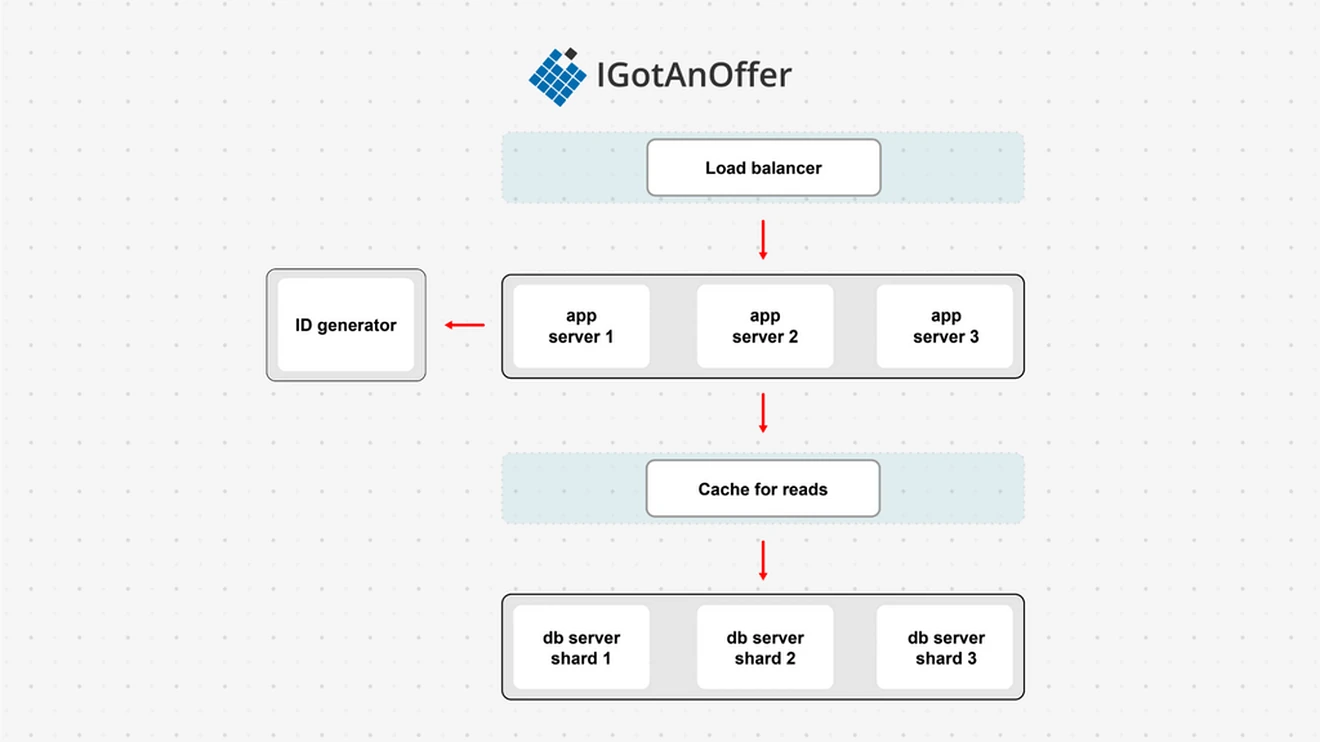
Interviewer: “I see you've added in a load-balancer?”
Candidate: “Yes. It's not part of the data design, but I thought I'd add it in for completeness.”
Identify bottlenecks ↑
Candidate: “Looking at the diagram, I guess a potential problem is that now the whole system relies on the central ID generator being up all the time. If it fails, then we won't be able to create new short codes, although reading would still work.”
Interviewer: “Yes, that sounds like it could be a problem. Is a potential failure of the central ID generator the only issue with it?”
Candidate: “I guess another problem could be that since there is only one ID generator, the speed and throughput of the system is limited by it. It would have to be very fast if it were to manage the amount of traffic, particularly in peak times.”
Interviewer: “That’s certainly a problem.”
Candidate: “I think we could fix it, though. We could make a few more ID generators, and the API servers could ‘round robin’ between them to get a new number. Each of the servers would be able to serve from an assigned range of numbers, so that they don't return the same numbers. So ID generator 1 would serve from say 0-50 billion, generator 2 from (50 billion +1) to 100 billion, and so on. Then if one ID generator goes down, the servers can still create short codes, just from a different range.”
Interviewer: “Making the ID generator effectively distributed as well.”
Candidate: “Yes, exactly.”
Dive into a specific component ↑
Candidate: “If you’re okay with it, I’d like to dive deeper into this ID generation function. How does that sound to you?”
Interviewer: “Sounds interesting, continue.”
Candidate: “Well, if we extend the concept of predefined ranges, instead of returning a single ID, we could return a list of numbers to the application servers. That way things are sped up, as the application servers do not need to call the ID generators on each call, making it even more reliable. They can assign a short code from the list of numbers, and only when they run out do they need to call one of the ID generator servers again.”
Interviewer: “So extra reliability and speed at the same time?”
Candidate: “Yeah! I'm not used it, but I've seen systems like ZooKeeper that I understand can manage this distributed key-generating scheme. Then we can use existing, reliable software for this part, instead of writing it from scratch, especially since it is a core function of the system.”
Interviewer: “That sounds promising.”
Candidate: “Another detail of the ID generator is what format does the ID take.”
Interviewer: “Can you expand on that?”
Candidate: “Well, we’ve discussed that the ID generators would generate numbers within ranges, in other words generate integers. If we simply return the integer number, it soon could become quite a large number. Our tiny URL would soon become a very long URL, the more the service is used. If we re-encoded that ID as a number in a number system that uses letters and numbers and is also case sensitive, which could be a base62 representation, then we would be able to constrain the length of the short code to be, well, short.”
Interviewer: “Ah, so after a year of generating short codes, we'd be at ID ‘60million*365 = 21 900 000 000’, which is 11 characters long. But if we represented it in a higher base, like base62, it would be something like ‘nU6aqs’, only 6 characters, making it a lot shorter.”
Candidate: “Yes, exactly that.”
Step 4: Bring it all together
Refine the architecture ↑
Candidate: “Okay, so here is the revised architecture with the the distributed ID generation part:”
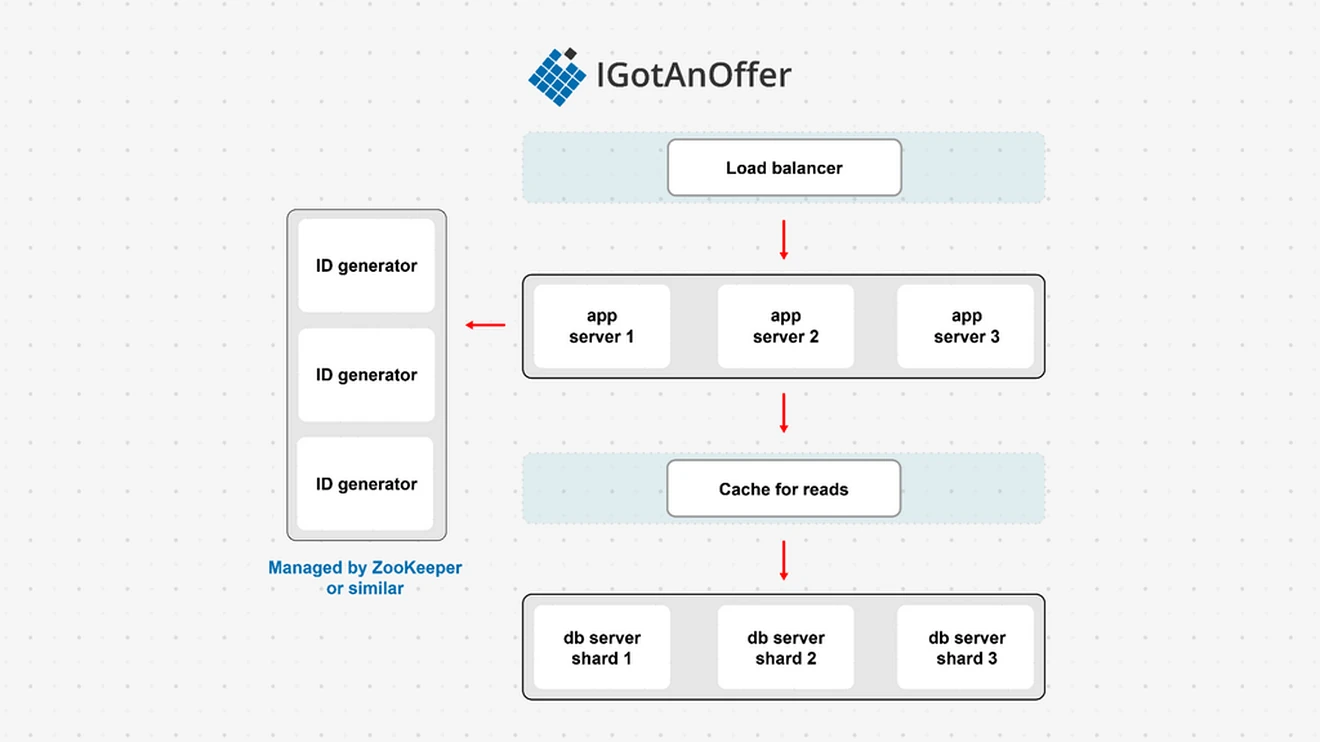
Interviewer: “Seems to be coming together.”
Candidate: “Yes. Though one thing we haven't settled on yet is the database technology. I'm thinking that since the schema is quite simple, and the link records are independent (i.e. they’re not related to each other), we are not constrained to traditional relational databases. Various NoSQL solutions have good support for sharding and horizontal scaling. I'm wondering whether a key-value store or a document-oriented database would be the better option.”
Interviewer: “Sounds logical. What would drive the consideration between the two technologies?”
Candidate: “I think it depends on how much information we are storing for each link, and how that information is used. In a key-value store, it is not usually straightforward to query on anything other than the key. We have a few other fields that might be useful to query on, especially the userId and expiry dates.”
Interviewer: “I think it's reasonable to assume that there would be queries at least occasionally beyond just the key.”
Candidate: “Okay, in that case, I think we should go with a document store, as it will provide that flexibility.”
Interviewer: “Makes sense.”
Candidate: “I think we just need to check that the design satisfies our initial objectives now.”
Interviewer: “Okay.”
Candidate: “The main requirement was that it generated a unique short URL given an arbitrary one. It also needs to scale to handle a large amount of traffic, perhaps up to about 600 writes per second, and 100-1000 times more reads. It should also be highly available. I think the design meets those requirements. It generates a short URL using a base62 representation of the record ID. It handles scale by making use of database sharding, a distributed key-generation system, and a cache for the most popular links. It also handles availability by having multiple servers, or redundancy, for each key component.”
Interviewer: “Good – it sounds like the only unknown part for you in the system is the lower level details of ZooKeeper?”
Candidate: “That's right. I haven't used it or configured it, but I would try to use ZooKeeper or something similar before writing a custom solution there. It sounds like a common problem that it solves, so I would think there are existing systems we could leverage.”
Questions for the interviewer ↑
Interviewer: “Okay, thanks. I think we're about out of time for this section, so do you have any other questions or concerns, whether for this design or something else?”
Candidate: “Yeah, one question I have is if this kind of blue sky design is a usual part of the job, or is it more weighted to maintaining existing solutions?”
Interviewer: “Well, at the scale that we operate, even seemingly small features can require a significant amount of engineering. As you mentioned earlier, a solution for a tiny URL system at low scale and availability requirements would simply be a lookup table, perhaps backed up to a file. So yes, there are often new ground-up solutions needed, and it is a large part of the work in this job.”
3. Good versus great system design candidates
In order to make the cut when interviewing at a company like Google, Facebook, or Amazon, you have to distinguish yourself from other candidates. Giving a good answer won’t be enough to get an offer. You’ll need to give a great answer if you want to make an impact.
So here are some details that make the difference between an interview that is just ok, and one that will impress your interviewer:
- Designs a complete system, but does not take hints from or interact with their interviewer
- Interacts with their interviewer, but is unable to change direction when prompted to do so
- Identifies metrics, but they aren’t clearly measurable or defined
- Provides numerical estimates for key system component properties, but does not justify them
- Finishes the design, but gets bogged down in unnecessary tangents or rabbit holes
- Finishes the design, but rushes through the final details and does not leave time for questions
- Understands the connection between most, but not all, core components of the design
- Considers trade-offs and compromises after being prompted to do so
- Neglects to assess the final design against its initial objectives
A “great” system design interview candidate:
- Designs a complete system while regularly checking in with their interviewer
- Is able to change direction and dive deeper on specific aspects when asked
- Plans their time wisely and does not have to rush through the final stages of the design
- Designs a complete high-level system, including measurable metrics, realistic requirements, and fully explained and interconnected components
- Proactively examines bottlenecks as well as the trade-offs of their alternatives
- Measures the final design against its initial objectives
- Is able to speak confidently about components with which they are familiar and ask for clarification when needed
Ultimately, being a great system design candidate boils down to having the right mix of technical knowledge and communication skills to both design the system and dialogue with their interviewer. For extra interview tips to improve your system design answers, take a look here.
So you’ll need to prepare for your interview by brushing up on both system design technical concepts and soft skills like communication. We’ve got a preparation plan to help you do that in our next section.
4. System design interview preparation
We've coached more than 15,000 people for interviews since 2018. As you can see from the information above, there is a lot of ground to cover when it comes to system design interview preparation. So, it’s best to take a systematic approach to make the most of your practice time.
Below, you’ll find links to free resources and three steps to help you prepare for your System Design interviews. For even more detail, take a look at our system design interview questions guide.
4.1 Learn the concepts
To be able to speak intelligently about system design, you’ll need to acquire a knowledge base of related concepts. Of course, this doesn’t mean that you need to know every detail related to sharding, load balancing, queues, etc.
However, you will need to understand the high-level function of typical system components. You'll also want to know how these components relate to each other, and any relevant industry standards or major trade-offs.
To help you get the foundational knowledge you need, we've put together a series of 9 system design concept guides.
Here's a the full list:
- Network protocols and proxies, which make it possible for any networked computers to talk to each other, no matter where they are or what hardware or software they’re running.
- Databases, integral components of the world’s biggest technology systems.
- Latency, throughput, and availability, three common metrics for measuring system performance.
- Load balancing, the process of distributing tasks over a set of computing nodes to improve the performance and reliability of the system.
- Leader election algorithms, which describe how a cluster of nodes without a leader can communicate with each other to choose exactly one of themselves to become the leader.
- Caching, a technique that stores copies of frequently used application data in a layer of smaller, faster memory in order to compute costs and to improve data retrieval times and throughput.
- Sharding, the horizontal scaling of a database system that is accomplished by breaking the database up into smaller “shards,” which are separate database servers that all contain a subset of the overall dataset.
- Polling, SSE, and WebSockets, techniques for streaming high volumes of data to or from a server.
- Queues and pub-sub, mechanisms that allow a system to process messages asynchronously, avoiding bottlenecks and help the system to operate more efficiently.
With those concepts in mind, let’s work out an approach that you can apply to any system design problem.
4.2 Practice by yourself
Next, you’ll want to start getting some practice with typical system design interview questions. You can start by practicing with a couple of the example questions provided in our list of 31 system design interview questions. If you're applying for an AI/ML engineering role, check out our machine learning system design interview or generative AI system design interview guides.
If you're specifically targeting a Staff-level role, you can also check out our Staff system design interview guide for a deeper dive into what interviewers expect at this level.
We'd recommend that you attempt to solve the problem yourself, before you look at the provided solution. While you work, practice mapping out your answer on a real whiteboard or its online equivalent (e.g. excalidraw, sketchboard.me, a Google doc, etc.).
4.3 Practice with peers
Once you've done some individual practice, we would also strongly recommend that you practice solving system design questions with someone else interviewing you. If you have friends or peers who can do mock interviews with you, that's an option worth trying. It’s free, but be warned, you may come up against the following problems:
- It’s hard to know if the feedback you get is accurate
- They’re unlikely to have insider knowledge of interviews at your target company
- On peer platforms, people often waste your time by not showing up
For those reasons, many candidates skip peer mock interviews and go straight to mock interviews with an expert. You can learn more about the best system design mock interview services here.
4.4. Practice with experienced system design interviewers
In our experience, practicing real interviews with experts who can give you company-specific feedback makes a huge difference.
Find a system design interview coach so you can:
- Test yourself under real interview conditions
- Get accurate feedback from a real expert
- Build your confidence
- Get company-specific insights
- Save time by focusing your preparation
Landing a job at a big tech company often results in a $50,000 per year or more increase in total compensation. In our experience, three or four coaching sessions worth ~$500 make a significant difference in your ability to land the job. That’s an ROI of 100x!