Data science case studies are tough to crack: they’re open-ended, technical, and specific to the company. Interviewers use them to test your ability to break down complex problems and your use of analytical thinking to address business concerns.
So we’ve put together this guide to help you familiarize yourself with case studies at companies like Amazon, Google, and Meta, as well as how to prepare for them, using practice questions and a repeatable answer framework.
Here’s the first thing you need to know about tackling data science case studies: always start by asking clarifying questions, before jumping into your plan.
Let’s get started.
- What to expect in data science case study interviews
- How to approach data science case studies
- Sample cases from FAANG data science interviews
- How to prepare for data science case interviews
Click here to practice 1-on-1 with ex-FAANG interviewers
1. What to expect in data science case study interviews
Before we get into an answer method and practice questions for data science case studies, let’s take a look at what you can expect in this type of interview.
Of course, the exact interview process for data scientist candidates will depend on the company you’re applying to, but case studies generally appear in both the pre-onsite phone screens and during the final onsite or virtual loop.
These questions may take anywhere from 10 to 40 minutes to answer, depending on the depth and complexity that the interviewer is looking for. During the initial phone screens, the case studies are typically shorter and interspersed with other technical and/or behavioral questions. During the final rounds, they will likely take longer to answer and require a more detailed analysis.
While some candidates may have the opportunity to prepare in advance and present their conclusions during an interview round, most candidates work with the information the interviewer offers on the spot.
1.1 The types of data science case studies
Generally, there are two types of case studies:
- Analysis cases, which focus on how you translate user behavior into ideas and insights using data. These typically center around a product, feature, or business concern that’s unique to the company you’re interviewing with.
- Modeling cases, which are more overtly technical and focus on how you build and use machine learning and statistical models to address business problems.
The number of case studies that you’ll receive in each category will depend on the company and the position that you’ve applied for. Facebook, for instance, typically doesn’t give many machine learning modeling cases, whereas Amazon and TikTok does.
Also, some companies break these larger groups into smaller subcategories. For example, Facebook divides its analysis cases into two types: product interpretation and applied data.
You may also receive in-depth questions similar to case studies, which test your technical capabilities (e.g. coding, SQL), so if you’d like to learn more about how to answer coding interview questions, take a look here.
We’ll give you a step-by-step method that can be used to answer analysis and modeling cases in section 2. But first, let’s look at how interviewers will assess your answers.
1.2 What interviewers are looking for
We’ve researched accounts from ex-interviewers and data scientists to pinpoint the main criteria that interviewers look for in your answers. While the exact grading rubric will vary per company, this list from an ex-Google data scientist is a good overview of the biggest assessment areas:
- Structure: candidate can break down an ambiguous problem into clear steps
- Completeness: candidate is able to fully answer the question
- Soundness: candidate’s solution is feasible and logical
- Clarity: candidate’s explanations and methodology are easy to understand
- Speed: candidate manages time well and is able to come up with solutions quickly
You’ll be able to improve your skills in each of these categories by practicing data science case studies on your own, and by working with an answer framework. We’ll get into that next.
2. How to approach data science case studies
Approaching data science cases with a repeatable framework will not only add structure to your answer, but also help you manage your time and think clearly under the stress of interview conditions.
Let’s go over a framework that you can use in your interviews, then break it down with an example answer.
2.1 Data science case framework: CAPER

We've researched popular frameworks used by real data scientists, and consolidated them to be as memorable and useful in an interview setting as possible.
Try using the framework below to structure your thinking during the interview.
- Clarify: Start by asking questions. Case questions are ambiguous, so you’ll need to gather more information from the interviewer, while eliminating irrelevant data. The types of questions you’ll ask will depend on the case, but consider: what is the business objective? What data can I access? Should I focus on all customers or just in X region?
- Assume: Narrow the problem down by making assumptions and stating them to the interviewer for confirmation. (E.g. the statistical significance is X%, users are segmented based on XYZ, etc.) By the end of this step you should have constrained the problem into a clear goal.
- Plan: Now, begin to craft your solution. Take time to outline a plan, breaking it into manageable tasks. Once you’ve made your plan, explain each step that you will take to the interviewer, and ask if it sounds good to them.
- Execute: Carry out your plan, walking through each step with the interviewer. Depending on the type of case, you may have to prepare and engineer data, code, apply statistical algorithms, build a model, etc. In the majority of cases, you will need to end with business analysis.
- Review: Finally, tie your final solution back to the business objectives you and the interviewer had initially identified. Evaluate your solution, and whether there are any steps you could have added or removed to improve it.
Now that you’ve seen the framework, let’s take a look at how to implement it.
2.2 Sample answer using the CAPER framework
Below you’ll find an answer to a Facebook data science interview question from the Applied Data loop. This is an example that comes from Facebook’s data science interview prep materials, which you can find here.
Try this question:
Imagine that Facebook is building a product around high schools, starting with about 300 million users who have filled out a field with the name of their current high school. How would you find out how much of this data is real?
1. Clarify
First, we need to clarify the question, eliminating irrelevant data and pinpointing what is the most important. For example:
- What exactly does “real” mean in this context?
- Should we focus on whether the high school itself is real, or whether the user actually attended the high school they’ve named?
After discussing with the interviewer, we’ve decided to focus on whether the high school itself is real first, followed by whether the user actually attended the high school they’ve named.
2. Assume
Next, we’ll narrow the problem down and state our assumptions to the interviewer for confirmation. Here are some assumptions we could make in the context of this problem:
- The 300 million users are likely teenagers, given that they’re listing their current high school
- We can assume that a high school that is listed too few times is likely fake
- We can assume that a high school that is listed too many times (e.g. 10,000+ students) is likely fake
The interviewer has agreed with each of these assumptions, so we can now move on to the plan.
3. Plan
Next, it’s time to make a list of actionable steps and lay them out for the interviewer before moving on.
First, there are two approaches that we can identify:
- A high precision approach, which provides a list of people who definitely went to a confirmed high school
- A high recall approach, more similar to market sizing, which would provide a ballpark figure of people who went to a confirmed high school
As this is for a product that Facebook is currently building, the product use case likely calls for an estimate that is as accurate as possible. So we can go for the first approach, which will provide a more precise estimate of confirmed users listing a real high school.
Now, we list the steps that make up this approach:
- To find whether a high school is real: Draw a distribution with the number of students on the X axis, and the number of high schools on the Y axis, in order to find and eliminate the lower and upper bounds
- To find whether a student really went to a high school: use a user’s friend graph and location to determine the plausibility of the high school they’ve named
The interviewer has approved the plan, which means that it’s time to execute.
4. Execute
Step 1: Determining whether a high school is real
Going off of our plan, we’ll first start with the distribution.
We can use x1 to denote the lower bound, below which the number of times a high school is listed would be too small for a plausible school. x2 then denotes the upper bound, above which the high school has been listed too many times for a plausible school.
Here is what that would look like:
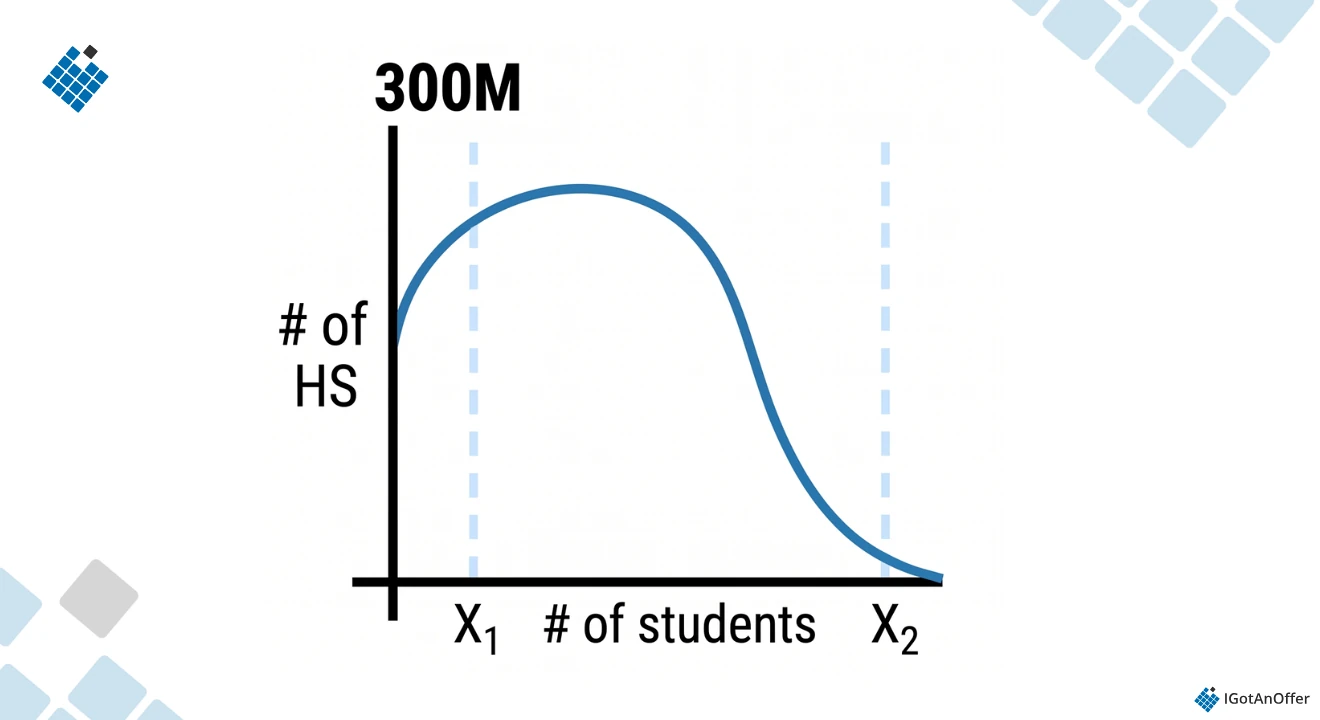
Be prepared to answer follow up questions. In this case, the interviewer may ask, “looking at this graph, what do you think x1 and x2 would be?”
Based on this distribution, we could say that x1 is approximately the 5th percentile, or somewhere around 100 students. So, out of 300 million students, if fewer than 100 students list “Applebee” high school, then this is most likely not a real high school.
x2 is likely around the 95th percentile, or potentially as high as the 99th percentile. Based on intuition, we could estimate that number around 10,000. So, if more than 10,000 students list “Applebee” high school, then this is most likely not real. Here is how that looks on the distribution:
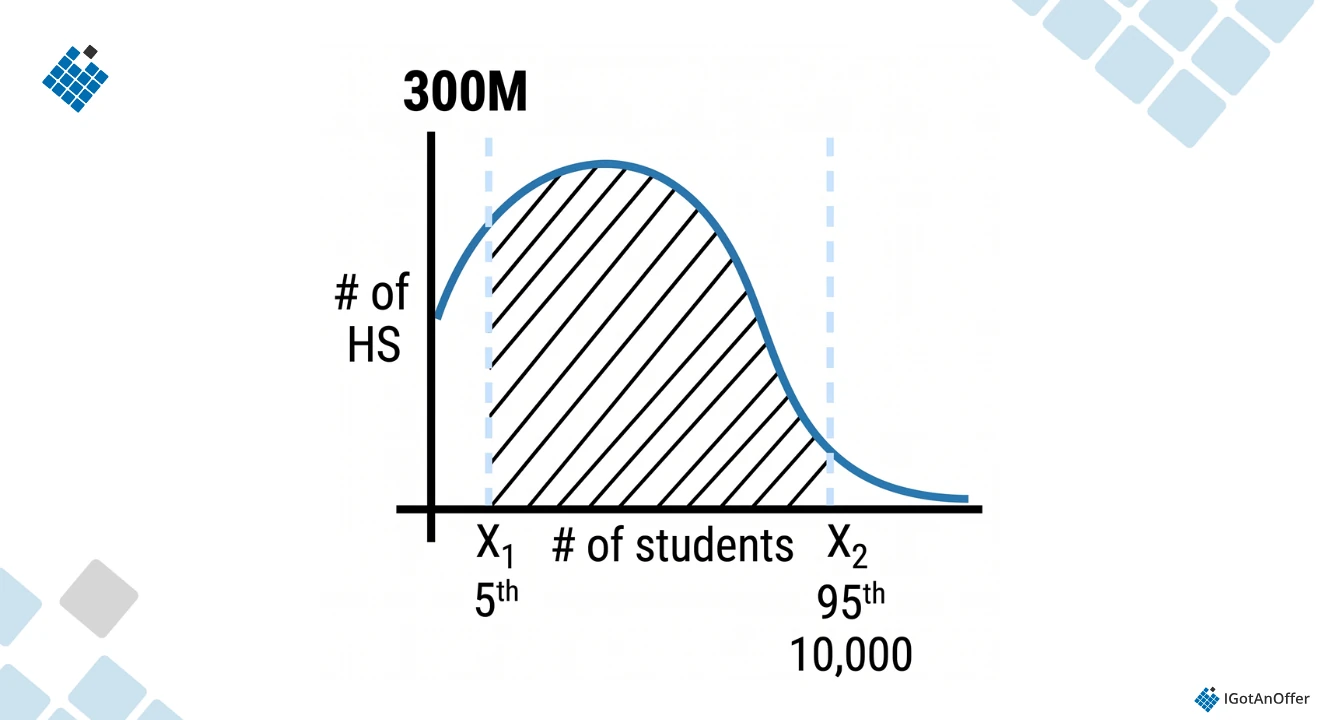
At this point, the interviewer may ask more follow-up questions, such as “how do we account for different high schools that share the same name?”
In this case, we could group by the schools’ name and location, rather than name alone. If the high school does not have a dedicated page that lists its location, we could deduce its location based on the city of the user that lists it.
Step 2: Determining whether a user went to the high school
A strong signal as to whether a user attended a specific high school would be their friend graph: a set number of friends would have to have listed the same current high school. For now, we’ll set that number at five friends.
Don’t forget to call out trade-offs and edge cases as you go. In this case, there could be a student who has recently moved, and so the high school they’ve listed does not reflect their actual current high school.
To solve this, we could rely on users to update their location to reflect the change. If users do not update their location and high school, this would present an edge case that we would need to work out later.
5. Review
To conclude, we could use the data from both the friend graph and the initial distribution to confirm the two signifiers: a high school is real, and the user really went there.
If enough users in the same location list the same high school, then it is likely that the high school is real, and that the users really attend it. If there are not enough users in the same location that list the same high school, then it is likely that the high school is not real, and the users do not actually attend it.
3. Sample cases from FAANG data science interviews
Having worked through the sample problem above, try out the different kinds of case studies that have been asked in data science interviews at FAANG companies. We’ve divided the questions into types of cases, as well as by company.
For more information about each of these companies’ data science interviews, take a look at these guides:
- Meta data scientist interview guide
- Amazon data scientist interview guide
- Amazon applied scientist interview guide
- Google data scientist interview guide
- Uber data scientist interview guide
- TikTok data scientist interview guide
- OpenAI data scientist interview guide
Now let’s get into the questions. This is a selection of real data scientist interview questions, according to data from Glassdoor.
Data science case studies
Facebook - Analysis (product interpretation)
- How would you measure the success of a product?
- What KPIs would you use to measure the success of the newsfeed?
- Friends acceptance rate decreases 15% after a new notifications system is launched - how would you investigate?
Facebook - Analysis (applied data)
- How would you evaluate the impact for teenagers when their parents join Facebook?
- How would you decide to launch or not if engagement within a specific cohort decreased while all the rest increased?
- How would you set up an experiment to understand feature change in Instagram stories?
Amazon - modeling
- How would you improve a classification model that suffers from low precision?
- When you have time series data by month, and it has large data records, how will you find significant differences between this month and previous month?
Google - Analysis
- You have a google app and you make a change. How do you test if a metric has increased or not?
- How do you detect viruses or inappropriate content on YouTube?
- How would you compare if upgrading the android system produces more searches?
4. How to prepare for data science case interviews
We've coached more than 15,000 people for interviews since 2018. There are essentially three activities you can do to practice for interviews. Here’s what we've learned about each of them.
4.1 Learn by yourself
Learning by yourself is an essential first step. For more information on how to prepare for data science interviews as a whole, take a look at our guide on data science interview prep.
Once you’re in command of the subject matter, you’ll want to practice answering questions. But by yourself, you can’t simulate thinking on your feet or the pressure of performing in front of a stranger. Plus, there are no unexpected follow-up questions and no feedback.
That’s why many candidates try to practice with friends or peers.
4.2 Practice with peers
If you have friends or peers who can do mock interviews with you, that's an option worth trying. It’s free, but be warned, you may come up against the following problems:
- It’s hard to know if the feedback you get is accurate
- They’re unlikely to have insider knowledge of interviews at your target company
- On peer platforms, people often waste your time by not showing up
For those reasons, many candidates skip peer mock interviews and go straight to mock interviews with an expert.
4.3 Practice with experienced tech interviewers
In our experience, practicing real interviews with experts who can give you company-specific feedback makes a huge difference.
Find a data science interview coach so you can:
- Test yourself under real interview conditions
- Get accurate feedback from a real expert
- Build your confidence
- Get company-specific insights
- Learn how to tell the right stories, better.
- Save time by focusing your preparation
Landing a job at a big tech company often results in a $50,000 per year or more increase in total compensation. In our experience, three or four coaching sessions worth ~$500 make a significant difference in your ability to land the job. That’s an ROI of 100x!
Click here to book data science mock interviews with experienced FAANG interviewers